ImageNetVC: Zero- and Few-Shot Visual Commonsense Evaluation on 1000 ImageNet Categories
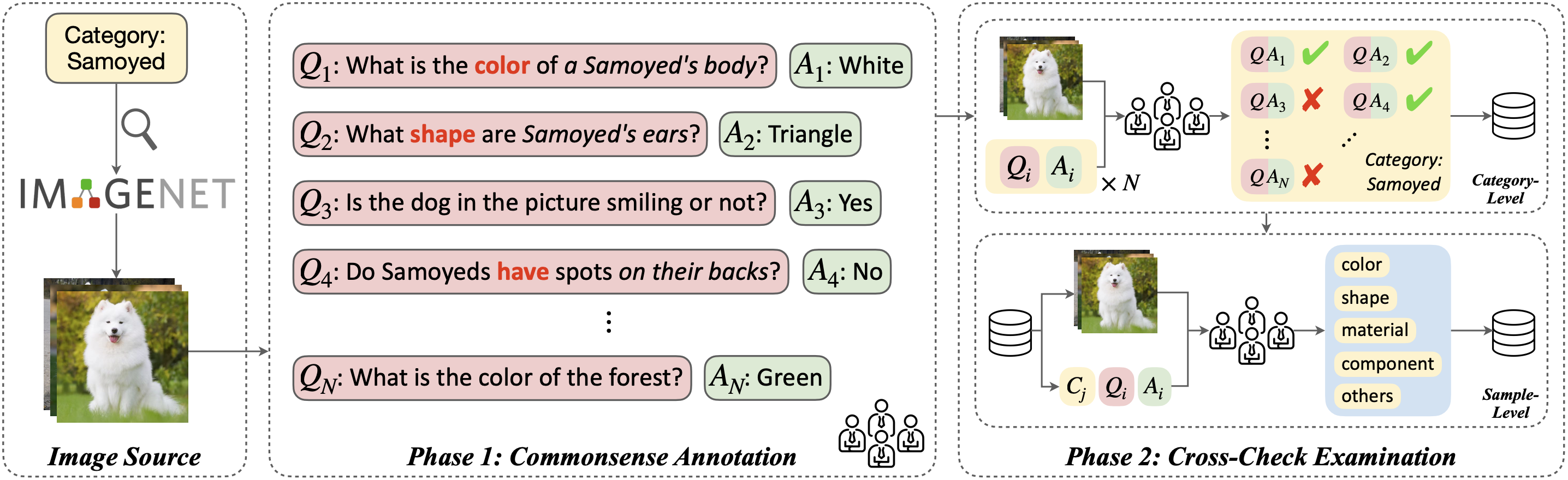
Recently, Large Language Models (LLMs) have been serving as general-purpose interfaces, posing a significant demand for comprehensive visual knowledge. However, it remains unclear how well current LLMs and their visually augmented counterparts (VaLMs) can master visual commonsense knowledge. To investigate this, we propose ImageNetVC, a human-annotated dataset specifically designed for zero- and few-shot visual commonsense evaluation across 1,000 ImageNet categories. Utilizing ImageNetVC, we benchmark the fundamental visual commonsense knowledge of both unimodal LLMs and VaLMs. Furthermore, we analyze the factors affecting the visual commonsense knowledge of large-scale models, providing insights into the development of language models enriched with visual commonsense knowledge. Our code and dataset are available at https://github.com/hemingkx/ImageNetVC.
PDF Abstract

 ImageNet
ImageNet
 Relative Size
Relative Size
