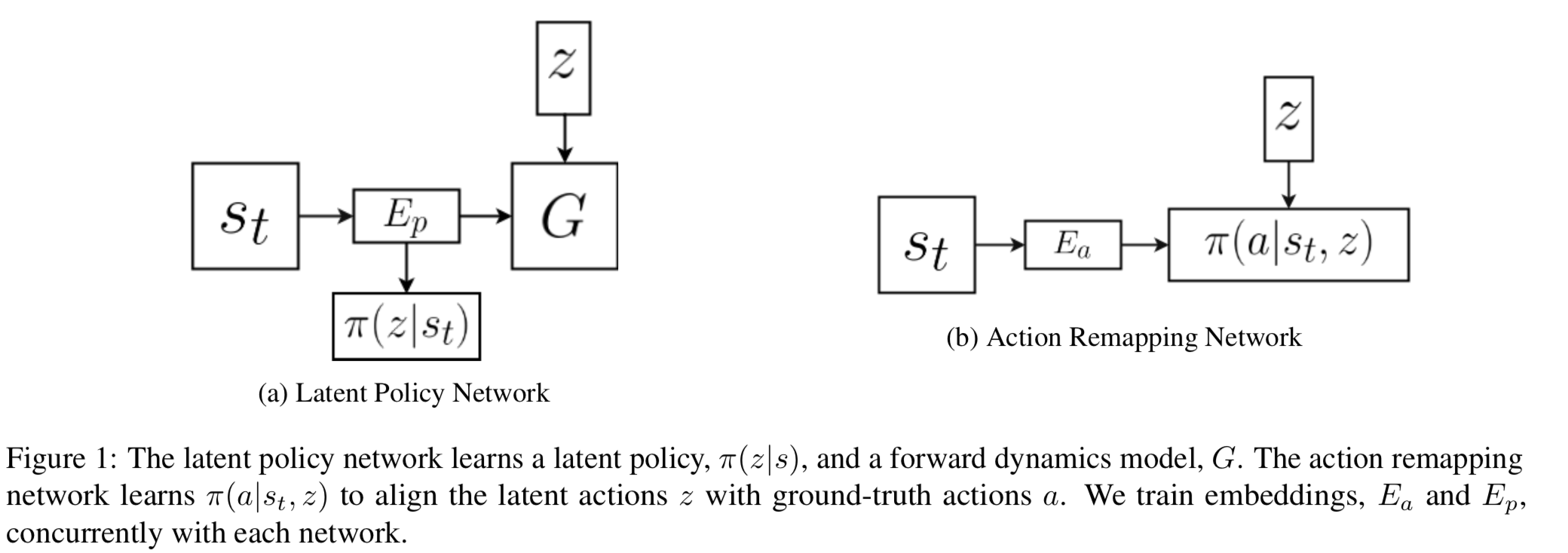
Imitating Latent Policies from Observation
In this paper, we describe a novel approach to imitation learning that infers latent policies directly from state observations. We introduce a method that characterizes the causal effects of latent actions on observations while simultaneously predicting their likelihood. We then outline an action alignment procedure that leverages a small amount of environment interactions to determine a mapping between the latent and real-world actions. We show that this corrected labeling can be used for imitating the observed behavior, even though no expert actions are given. We evaluate our approach within classic control environments and a platform game and demonstrate that it performs better than standard approaches. Code for this work is available at https://github.com/ashedwards/ILPO.
PDF Abstract


