Improving BERT Fine-Tuning via Self-Ensemble and Self-Distillation
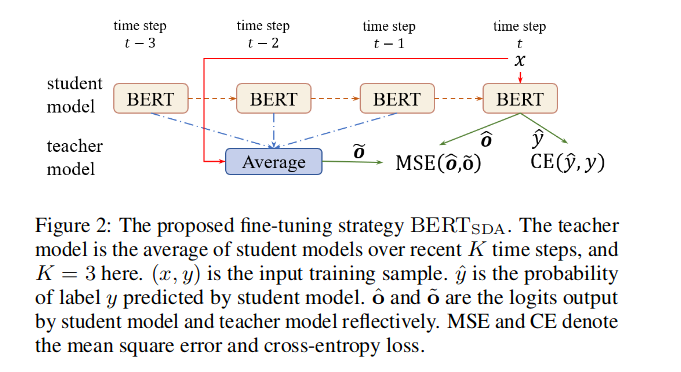
Fine-tuning pre-trained language models like BERT has become an effective way in NLP and yields state-of-the-art results on many downstream tasks. Recent studies on adapting BERT to new tasks mainly focus on modifying the model structure, re-designing the pre-train tasks, and leveraging external data and knowledge. The fine-tuning strategy itself has yet to be fully explored. In this paper, we improve the fine-tuning of BERT with two effective mechanisms: self-ensemble and self-distillation. The experiments on text classification and natural language inference tasks show our proposed methods can significantly improve the adaption of BERT without any external data or knowledge.
PDF AbstractCode




Datasets
 MultiNLI
MultiNLI
 IMDb Movie Reviews
IMDb Movie Reviews
 SNLI
SNLI
Results from the Paper
Submit
results from this paper
to get state-of-the-art GitHub badges and help the
community compare results to other papers.
