Improving Language Model Negotiation with Self-Play and In-Context Learning from AI Feedback
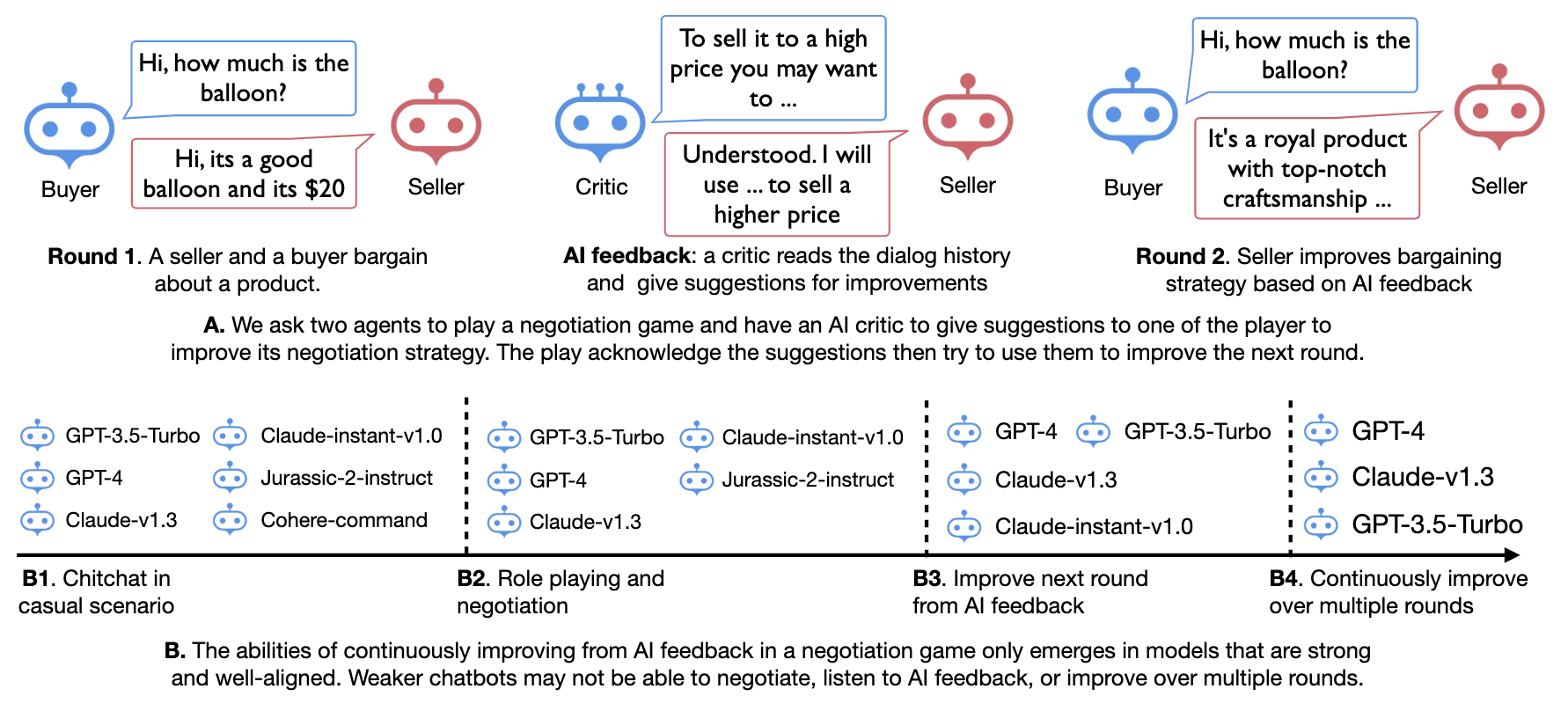
We study whether multiple large language models (LLMs) can autonomously improve each other in a negotiation game by playing, reflecting, and criticizing. We are interested in this question because if LLMs were able to improve each other, it would imply the possibility of creating strong AI agents with minimal human intervention. We ask two LLMs to negotiate with each other, playing the roles of a buyer and a seller, respectively. They aim to reach a deal with the buyer targeting a lower price and the seller a higher one. A third language model, playing the critic, provides feedback to a player to improve the player's negotiation strategies. We let the two agents play multiple rounds, using previous negotiation history and AI feedback as in-context demonstrations to improve the model's negotiation strategy iteratively. We use different LLMs (GPT and Claude) for different roles and use the deal price as the evaluation metric. Our experiments reveal multiple intriguing findings: (1) Only a subset of the language models we consider can self-play and improve the deal price from AI feedback, weaker models either do not understand the game's rules or cannot incorporate AI feedback for further improvement. (2) Models' abilities to learn from the feedback differ when playing different roles. For example, it is harder for Claude-instant to improve as the buyer than as the seller. (3) When unrolling the game to multiple rounds, stronger agents can consistently improve their performance by meaningfully using previous experiences and iterative AI feedback, yet have a higher risk of breaking the deal. We hope our work provides insightful initial explorations of having models autonomously improve each other with game playing and AI feedback.
PDF Abstract

