Improving Neural Cross-Lingual Summarization via Employing Optimal Transport Distance for Knowledge Distillation
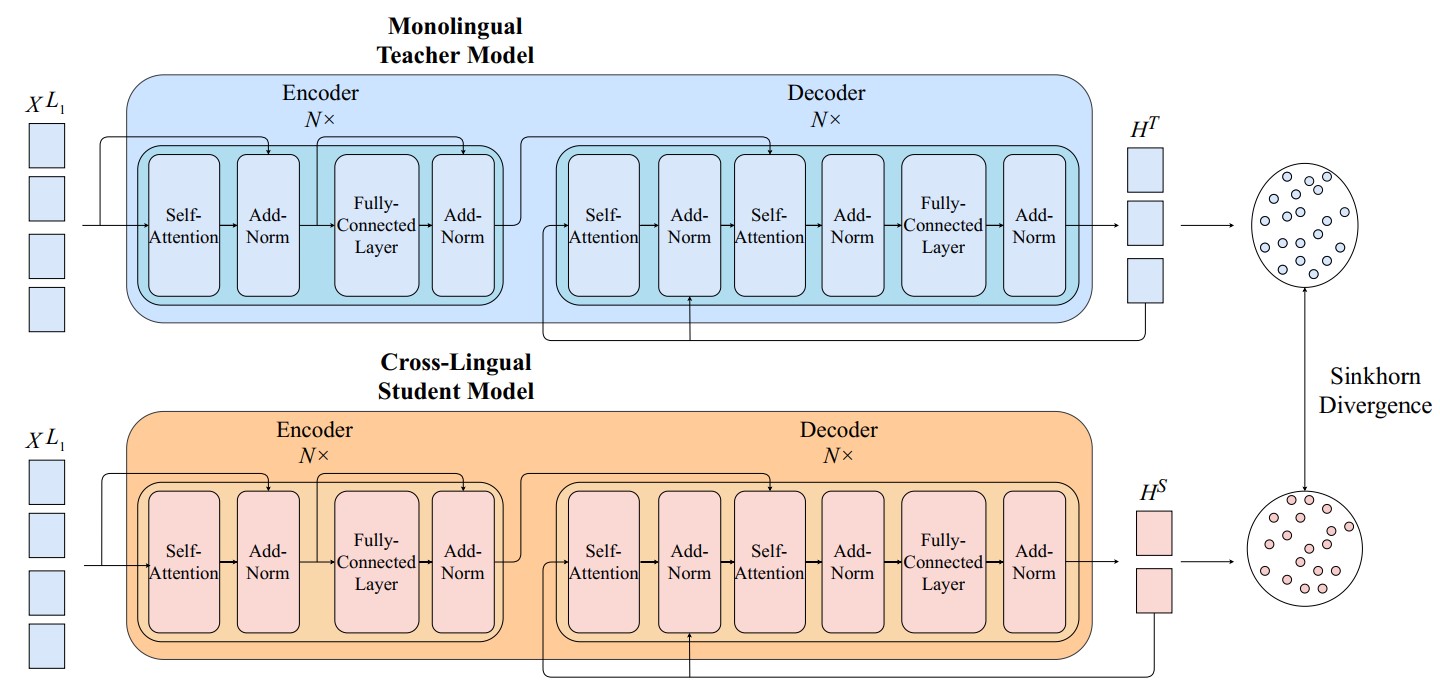
Current state-of-the-art cross-lingual summarization models employ multi-task learning paradigm, which works on a shared vocabulary module and relies on the self-attention mechanism to attend among tokens in two languages. However, correlation learned by self-attention is often loose and implicit, inefficient in capturing crucial cross-lingual representations between languages. The matter worsens when performing on languages with separate morphological or structural features, making the cross-lingual alignment more challenging, resulting in the performance drop. To overcome this problem, we propose a novel Knowledge-Distillation-based framework for Cross-Lingual Summarization, seeking to explicitly construct cross-lingual correlation by distilling the knowledge of the monolingual summarization teacher into the cross-lingual summarization student. Since the representations of the teacher and the student lie on two different vector spaces, we further propose a Knowledge Distillation loss using Sinkhorn Divergence, an Optimal-Transport distance, to estimate the discrepancy between those teacher and student representations. Due to the intuitively geometric nature of Sinkhorn Divergence, the student model can productively learn to align its produced cross-lingual hidden states with monolingual hidden states, hence leading to a strong correlation between distant languages. Experiments on cross-lingual summarization datasets in pairs of distant languages demonstrate that our method outperforms state-of-the-art models under both high and low-resourced settings.
PDF Abstract


 WikiLingua
WikiLingua
