Improving Spoken Language Identification with Map-Mix
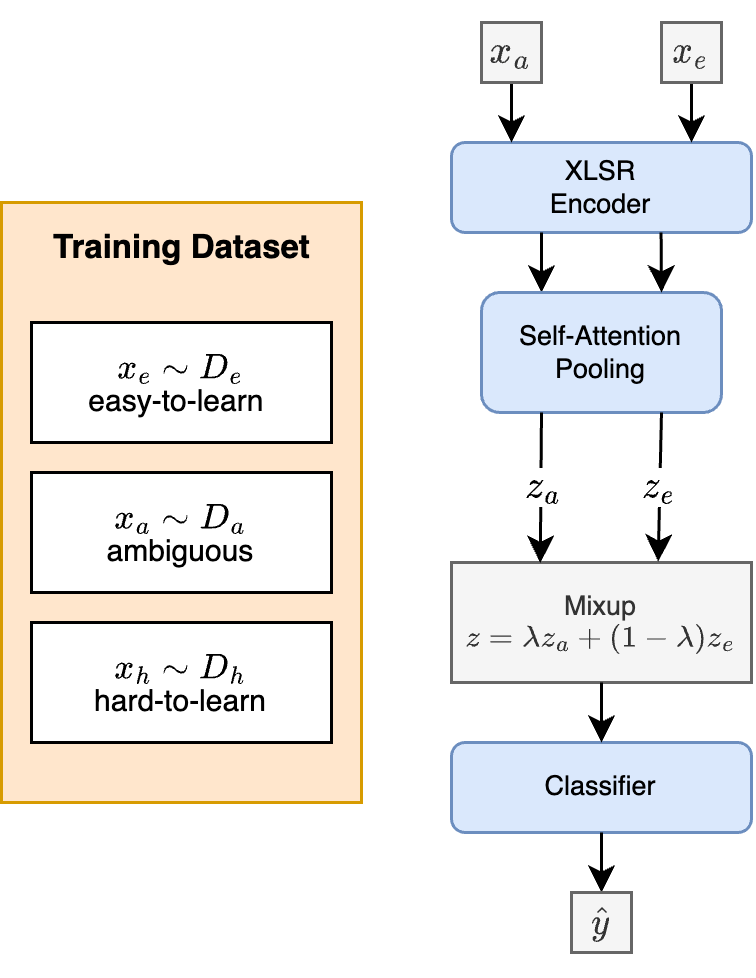
The pre-trained multi-lingual XLSR model generalizes well for language identification after fine-tuning on unseen languages. However, the performance significantly degrades when the languages are not very distinct from each other, for example, in the case of dialects. Low resource dialect classification remains a challenging problem to solve. We present a new data augmentation method that leverages model training dynamics of individual data points to improve sampling for latent mixup. The method works well in low-resource settings where generalization is paramount. Our datamaps-based mixup technique, which we call Map-Mix improves weighted F1 scores by 2% compared to the random mixup baseline and results in a significantly well-calibrated model. The code for our method is open sourced on https://github.com/skit-ai/Map-Mix.
PDF Abstract

