In Defense of Grid Features for Visual Question Answering
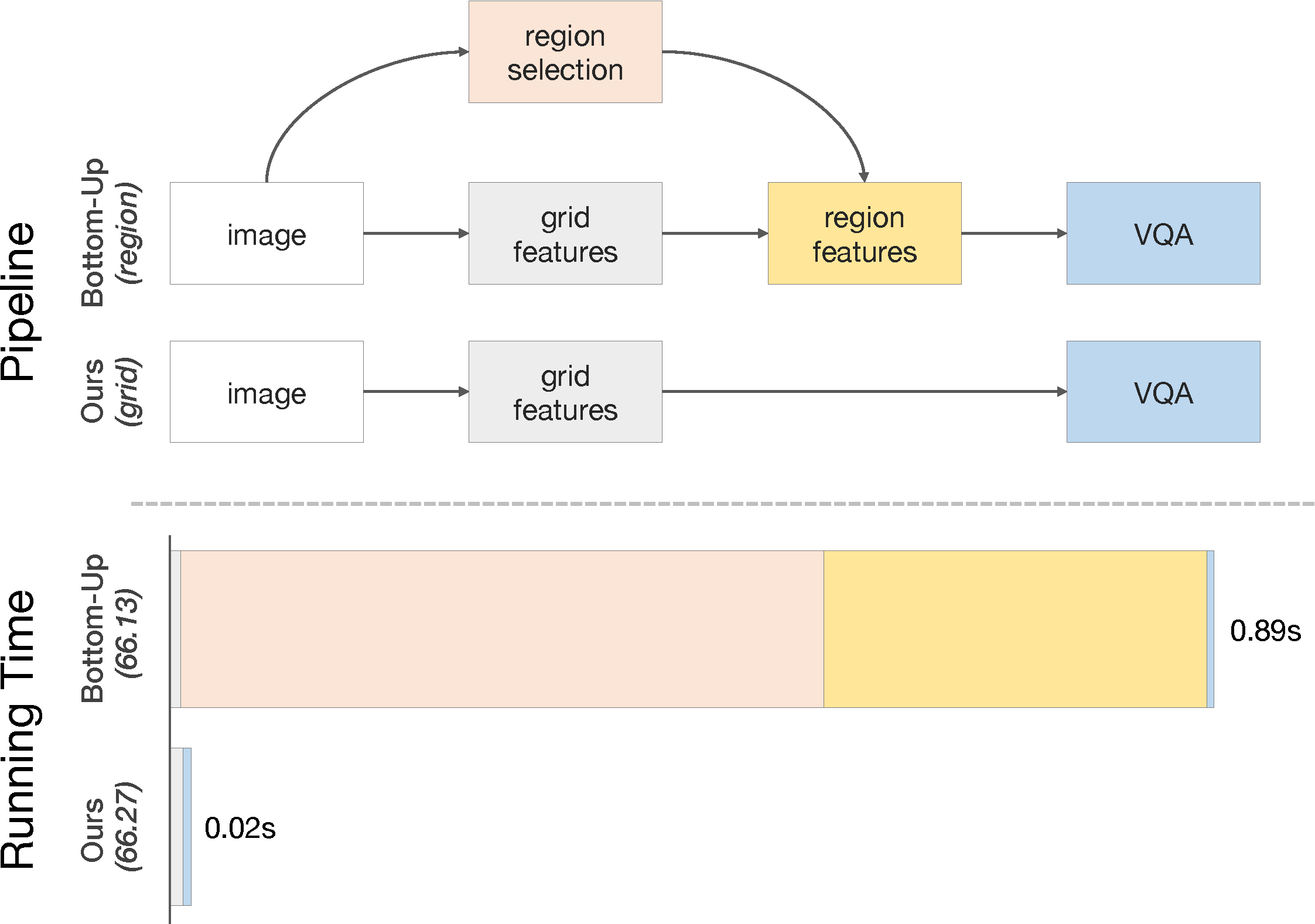
Popularized as 'bottom-up' attention, bounding box (or region) based visual features have recently surpassed vanilla grid-based convolutional features as the de facto standard for vision and language tasks like visual question answering (VQA). However, it is not clear whether the advantages of regions (e.g. better localization) are the key reasons for the success of bottom-up attention. In this paper, we revisit grid features for VQA, and find they can work surprisingly well - running more than an order of magnitude faster with the same accuracy (e.g. if pre-trained in a similar fashion). Through extensive experiments, we verify that this observation holds true across different VQA models (reporting a state-of-the-art accuracy on VQA 2.0 test-std, 72.71), datasets, and generalizes well to other tasks like image captioning. As grid features make the model design and training process much simpler, this enables us to train them end-to-end and also use a more flexible network design. We learn VQA models end-to-end, from pixels directly to answers, and show that strong performance is achievable without using any region annotations in pre-training. We hope our findings help further improve the scientific understanding and the practical application of VQA. Code and features will be made available.
PDF Abstract CVPR 2020 PDF CVPR 2020 AbstractCode





 ImageNet
ImageNet
 MS COCO
MS COCO
 Visual Question Answering
Visual Question Answering
 Visual Genome
Visual Genome
 Visual Question Answering v2.0
Visual Question Answering v2.0
 VizWiz
VizWiz
Results from the Paper

| Task | Dataset | Model | Metric Name | Metric Value | Global Rank | Benchmark |
|---|---|---|---|---|---|---|
| Visual Question Answering (VQA) | VQA v2 test-dev | X-101 grid features + MCAN | Accuracy | 72.59 | # 22 | |
| Visual Question Answering (VQA) | VQA v2 test-std | Single, w/o VLP | overall | 74.16 | # 18 | |
| yes/no | 89.18 | # 10 | ||||
| number | 58.01 | # 9 | ||||
| other | 64.77 | # 9 | ||||
| Visual Question Answering (VQA) | VQA v2 test-std | X-101 grid features + MCAN | overall | 72.71 | # 21 |
