Increasing the Inference and Learning Speed of Tsetlin Machines with Clause Indexing
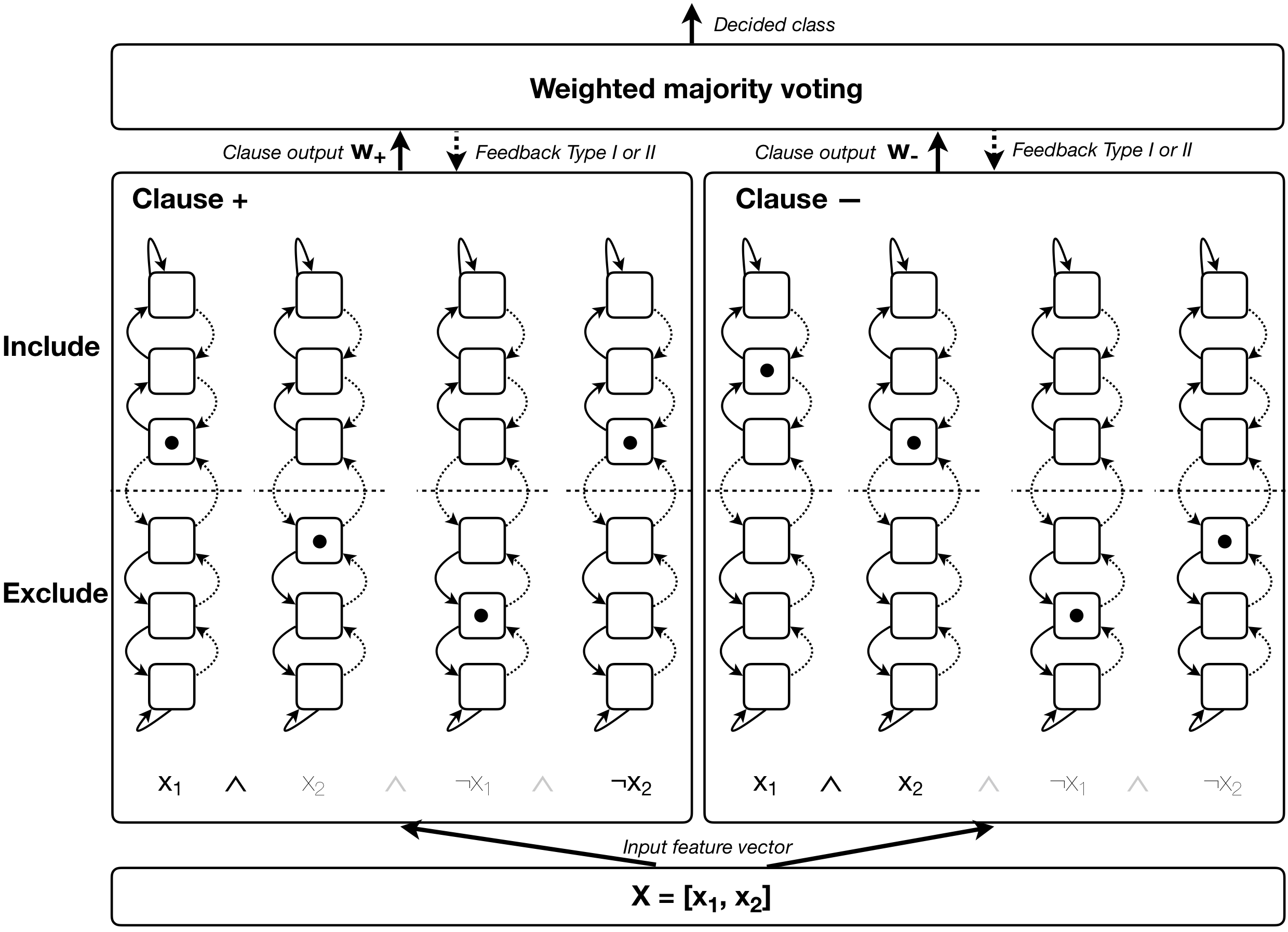
The Tsetlin Machine (TM) is a machine learning algorithm founded on the classical Tsetlin Automaton (TA) and game theory. It further leverages frequent pattern mining and resource allocation principles to extract common patterns in the data, rather than relying on minimizing output error, which is prone to overfitting. Unlike the intertwined nature of pattern representation in neural networks, a TM decomposes problems into self-contained patterns, represented as conjunctive clauses. The clause outputs, in turn, are combined into a classification decision through summation and thresholding, akin to a logistic regression function, however, with binary weights and a unit step output function. In this paper, we exploit this hierarchical structure by introducing a novel algorithm that avoids evaluating the clauses exhaustively. Instead we use a simple look-up table that indexes the clauses on the features that falsify them. In this manner, we can quickly evaluate a large number of clauses through falsification, simply by iterating through the features and using the look-up table to eliminate those clauses that are falsified. The look-up table is further structured so that it facilitates constant time updating, thus supporting use also during learning. We report up to 15 times faster classification and three times faster learning on MNIST and Fashion-MNIST image classification, and IMDb sentiment analysis.
PDF Abstract


 Fashion-MNIST
Fashion-MNIST
