InfoBatch: Lossless Training Speed Up by Unbiased Dynamic Data Pruning
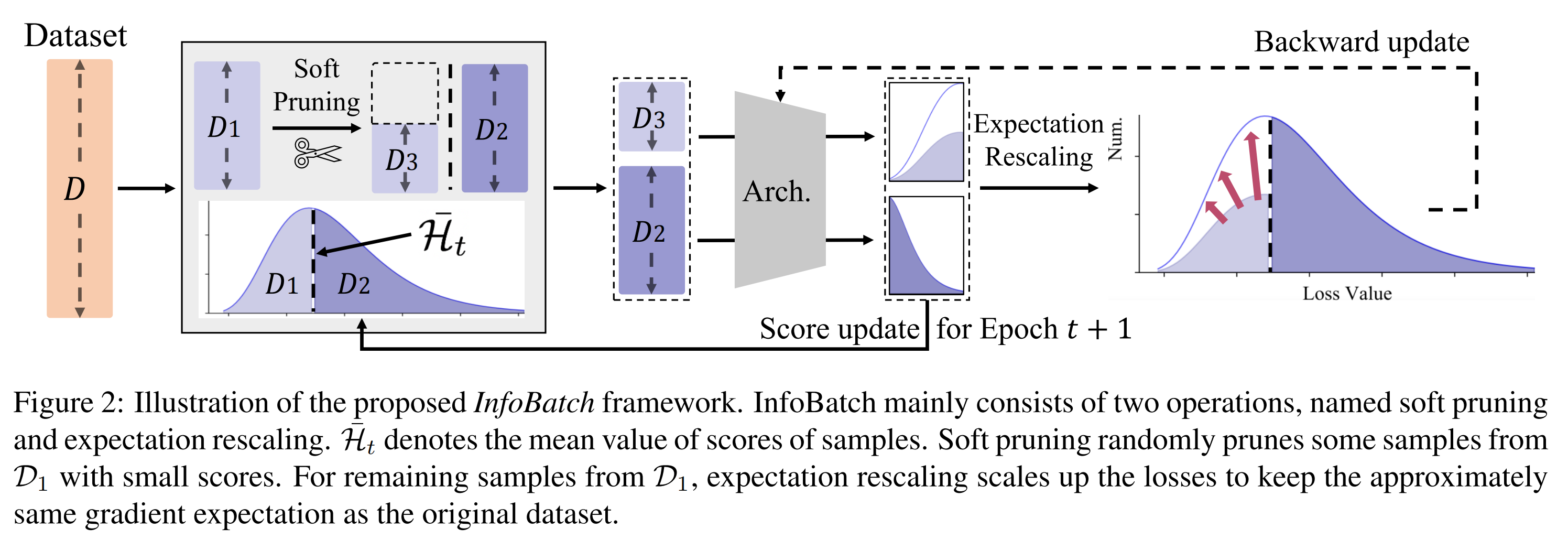
Data pruning aims to obtain lossless performances with less overall cost. A common approach is to filter out samples that make less contribution to the training. This could lead to gradient expectation bias compared to the original data. To solve this problem, we propose \textbf{InfoBatch}, a novel framework aiming to achieve lossless training acceleration by unbiased dynamic data pruning. Specifically, InfoBatch randomly prunes a portion of less informative samples based on the loss distribution and rescales the gradients of the remaining samples to approximate the original gradient. As a plug-and-play and architecture-agnostic framework, InfoBatch consistently obtains lossless training results on classification, semantic segmentation, vision pertaining, and instruction fine-tuning tasks. On CIFAR10/100, ImageNet-1K, and ADE20K, InfoBatch losslessly saves 40\% overall cost. For pertaining MAE and diffusion model, InfoBatch can respectively save 24.8\% and 27\% cost. For LLaMA instruction fine-tuning, InfoBatch is also able to save 20\% cost and is compatible with coreset selection methods. The code is publicly available at \href{https://github.com/henryqin1997/InfoBatch}{github.com/NUS-HPC-AI-Lab/InfoBatch}.
PDF Abstract

 ImageNet
ImageNet
 FFHQ
FFHQ
 ADE20K
ADE20K
