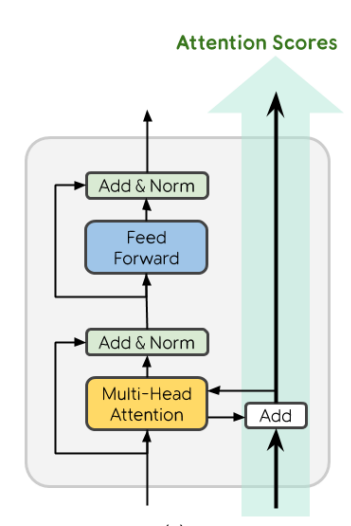
RealFormer: Transformer Likes Residual Attention
Transformer is the backbone of modern NLP models. In this paper, we propose RealFormer, a simple and generic technique to create Residual Attention Layer Transformer networks that significantly outperform the canonical Transformer and its variants (BERT, ETC, etc.) on a wide spectrum of tasks including Masked Language Modeling, GLUE, SQuAD, Neural Machine Translation, WikiHop, HotpotQA, Natural Questions, and OpenKP. We also observe empirically that RealFormer stabilizes training and leads to models with sparser attention. Source code and pre-trained checkpoints for RealFormer can be found at https://github.com/google-research/google-research/tree/master/realformer.
PDF Abstract Findings (ACL) 2021 PDF Findings (ACL) 2021 AbstractCode











 GLUE
GLUE
 SST
SST
 SQuAD
SQuAD
 MultiNLI
MultiNLI
 QNLI
QNLI
 Natural Questions
Natural Questions
 MRPC
MRPC
 CoLA
CoLA
 HotpotQA
HotpotQA
 Quora
Quora
 WikiHop
WikiHop
 Quora Question Pairs
Quora Question Pairs
Results from the Paper

Methods
Absolute Position Encodings •
Adam •
BPE •
Contrastive Predictive Coding •
Dense Connections •
Dropout •
ETC •
Global-Local Attention •
InfoNCE •
Label Smoothing •
Layer Normalization •
Linear Layer •
Multi-Head Attention •
Position-Wise Feed-Forward Layer •
RealFormer •
Relative Position Encodings •
Residual Connection •
Scaled Dot-Product Attention •
Softmax •
Transformer
