Instance Segmentation for Chinese Character Stroke Extraction, Datasets and Benchmarks
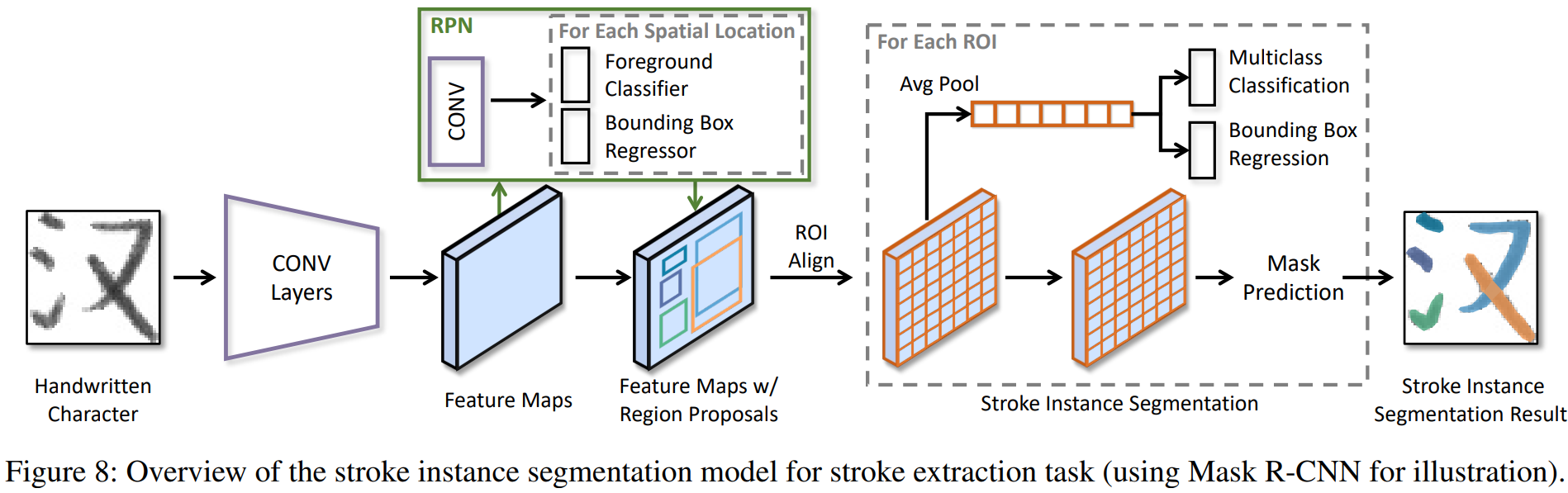
Stroke is the basic element of Chinese character and stroke extraction has been an important and long-standing endeavor. Existing stroke extraction methods are often handcrafted and highly depend on domain expertise due to the limited training data. Moreover, there are no standardized benchmarks to provide a fair comparison between different stroke extraction methods, which, we believe, is a major impediment to the development of Chinese character stroke understanding and related tasks. In this work, we present the first public available Chinese Character Stroke Extraction (CCSE) benchmark, with two new large-scale datasets: Kaiti CCSE (CCSE-Kai) and Handwritten CCSE (CCSE-HW). With the large-scale datasets, we hope to leverage the representation power of deep models such as CNNs to solve the stroke extraction task, which, however, remains an open question. To this end, we turn the stroke extraction problem into a stroke instance segmentation problem. Using the proposed datasets to train a stroke instance segmentation model, we surpass previous methods by a large margin. Moreover, the models trained with the proposed datasets benefit the downstream font generation and handwritten aesthetic assessment tasks. We hope these benchmark results can facilitate further research. The source code and datasets are publicly available at: https://github.com/lizhaoliu-Lec/CCSE.
PDF Abstract



 CCSE
CCSE
 ImageNet
ImageNet
