Instruction-Following Agents with Multimodal Transformer
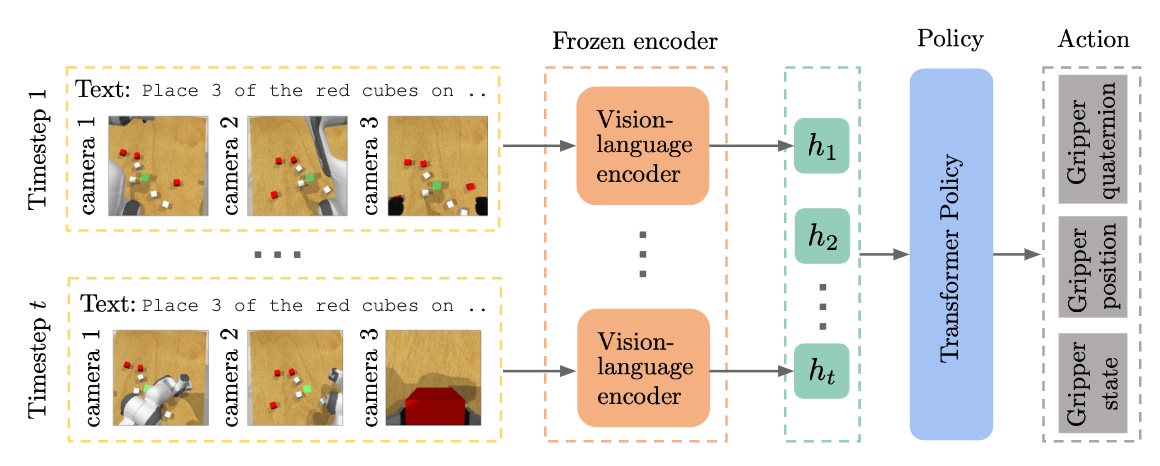
Humans are excellent at understanding language and vision to accomplish a wide range of tasks. In contrast, creating general instruction-following embodied agents remains a difficult challenge. Prior work that uses pure language-only models lack visual grounding, making it difficult to connect language instructions with visual observations. On the other hand, methods that use pre-trained multimodal models typically come with divided language and visual representations, requiring designing specialized network architecture to fuse them together. We propose a simple yet effective model for robots to solve instruction-following tasks in vision-based environments. Our \ours method consists of a multimodal transformer that encodes visual observations and language instructions, and a transformer-based policy that predicts actions based on encoded representations. The multimodal transformer is pre-trained on millions of image-text pairs and natural language text, thereby producing generic cross-modal representations of observations and instructions. The transformer-based policy keeps track of the full history of observations and actions, and predicts actions autoregressively. Despite its simplicity, we show that this unified transformer model outperforms all state-of-the-art pre-trained or trained-from-scratch methods in both single-task and multi-task settings. Our model also shows better model scalability and generalization ability than prior work.
PDF Abstract


 RLBench
RLBench
