Interactive Refinement of Cross-Lingual Word Embeddings
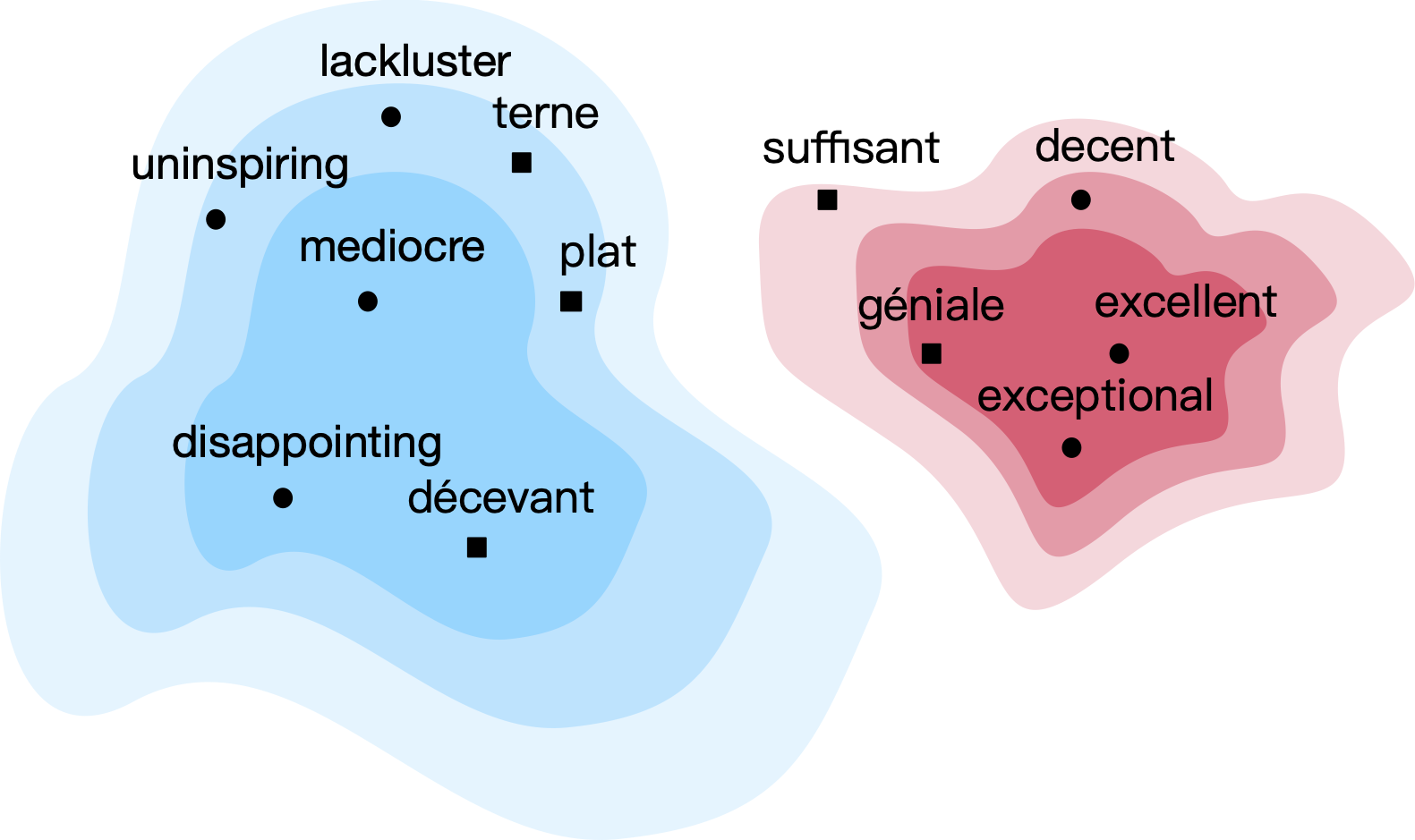
Cross-lingual word embeddings transfer knowledge between languages: models trained on high-resource languages can predict in low-resource languages. We introduce CLIME, an interactive system to quickly refine cross-lingual word embeddings for a given classification problem. First, CLIME ranks words by their salience to the downstream task. Then, users mark similarity between keywords and their nearest neighbors in the embedding space. Finally, CLIME updates the embeddings using the annotations. We evaluate CLIME on identifying health-related text in four low-resource languages: Ilocano, Sinhalese, Tigrinya, and Uyghur. Embeddings refined by CLIME capture more nuanced word semantics and have higher test accuracy than the original embeddings. CLIME often improves accuracy faster than an active learning baseline and can be easily combined with active learning to improve results.
PDF Abstract EMNLP 2020 PDF EMNLP 2020 Abstract




