Interpretable RNA Foundation Model from Unannotated Data for Highly Accurate RNA Structure and Function Predictions
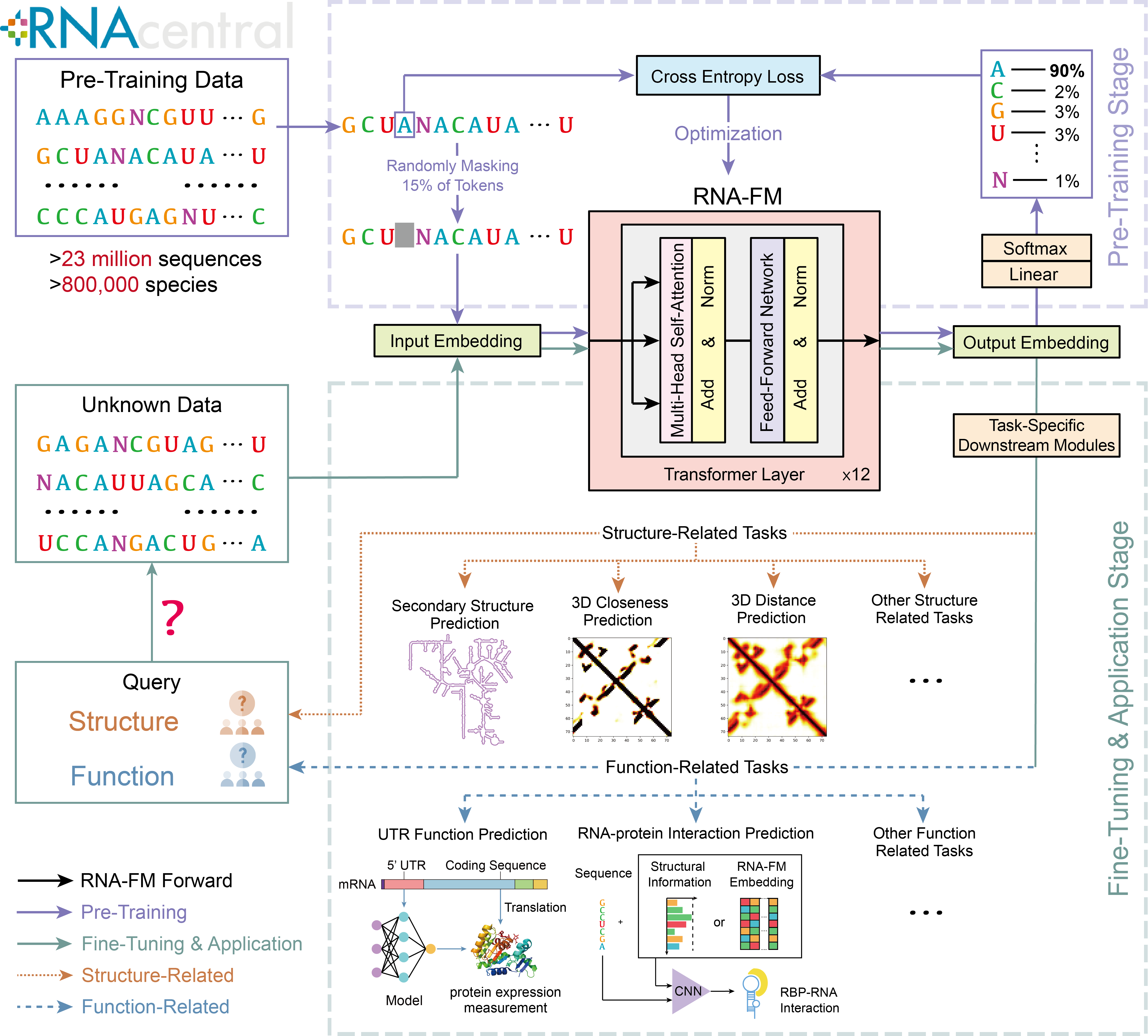
Non-coding RNA structure and function are essential to understanding various biological processes, such as cell signaling, gene expression, and post-transcriptional regulations. These are all among the core problems in the RNA field. With the rapid growth of sequencing technology, we have accumulated a massive amount of unannotated RNA sequences. On the other hand, expensive experimental observatory results in only limited numbers of annotated data and 3D structures. Hence, it is still challenging to design computational methods for predicting their structures and functions. The lack of annotated data and systematic study causes inferior performance. To resolve the issue, we propose a novel RNA foundation model (RNA-FM) to take advantage of all the 23 million non-coding RNA sequences through self-supervised learning. Within this approach, we discover that the pre-trained RNA-FM could infer sequential and evolutionary information of non-coding RNAs without using any labels. Furthermore, we demonstrate RNA-FM's effectiveness by applying it to the downstream secondary/3D structure prediction, SARS-CoV-2 genome structure and evolution prediction, protein-RNA binding preference modeling, and gene expression regulation modeling. The comprehensive experiments show that the proposed method improves the RNA structural and functional modelling results significantly and consistently. Despite only being trained with unlabelled data, RNA-FM can serve as the foundational model for the field.
PDF Abstract

