Interpretations are useful: penalizing explanations to align neural networks with prior knowledge
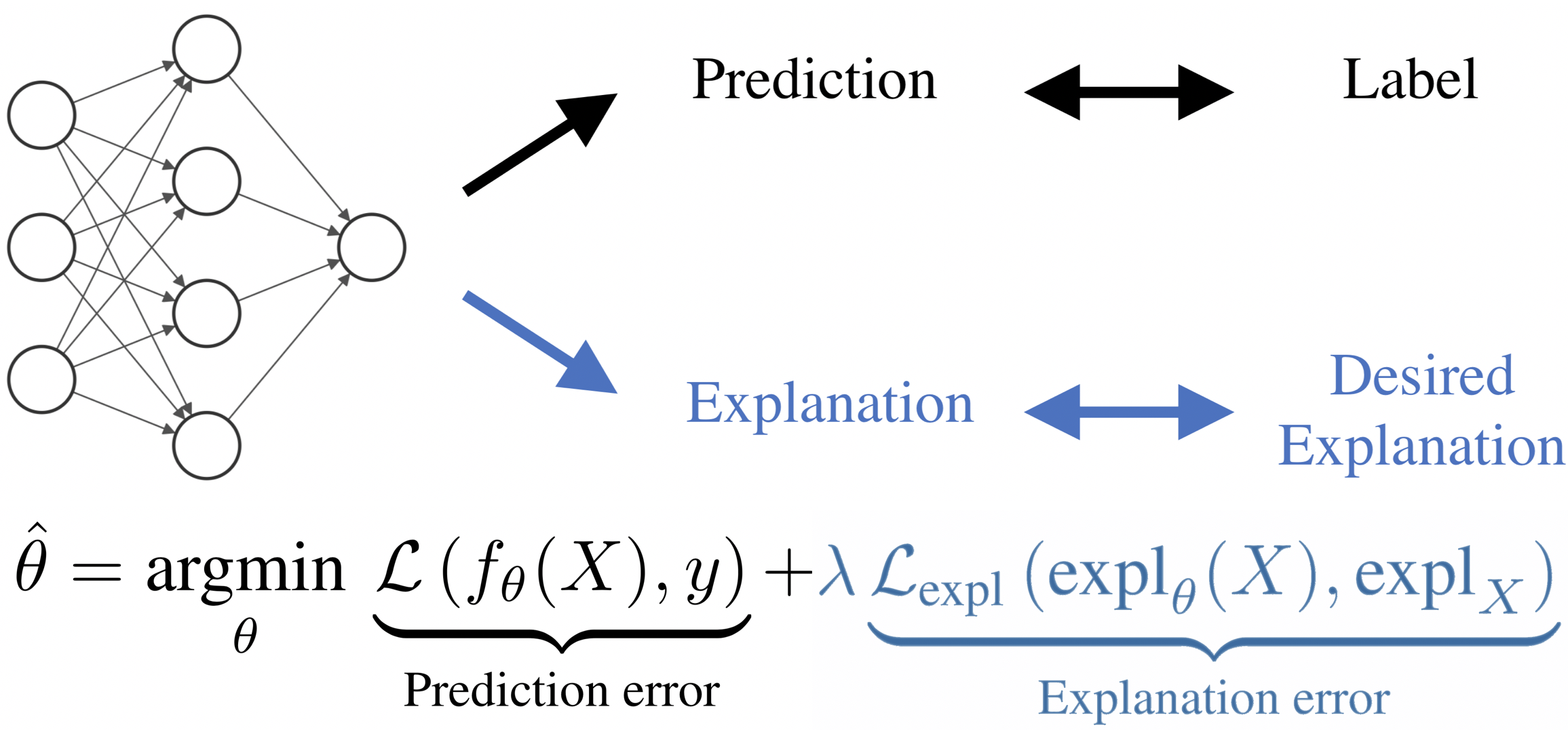
For an explanation of a deep learning model to be effective, it must provide both insight into a model and suggest a corresponding action in order to achieve some objective. Too often, the litany of proposed explainable deep learning methods stop at the first step, providing practitioners with insight into a model, but no way to act on it. In this paper, we propose contextual decomposition explanation penalization (CDEP), a method which enables practitioners to leverage existing explanation methods in order to increase the predictive accuracy of deep learning models. In particular, when shown that a model has incorrectly assigned importance to some features, CDEP enables practitioners to correct these errors by directly regularizing the provided explanations. Using explanations provided by contextual decomposition (CD) (Murdoch et al., 2018), we demonstrate the ability of our method to increase performance on an array of toy and real datasets.
PDF Abstract ICML 2020 PDF
 SST
SST
