Interpreting Deep Visual Representations via Network Dissection
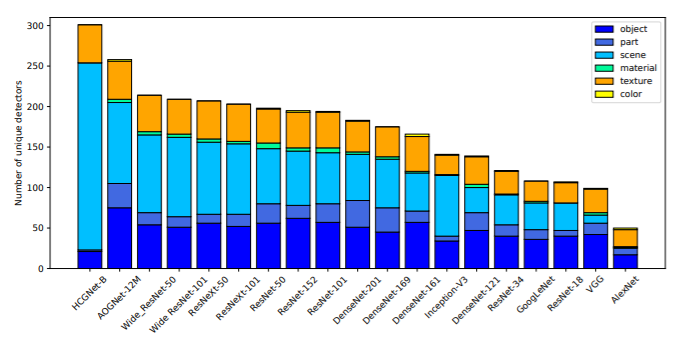
The success of recent deep convolutional neural networks (CNNs) depends on learning hidden representations that can summarize the important factors of variation behind the data. However, CNNs often criticized as being black boxes that lack interpretability, since they have millions of unexplained model parameters. In this work, we describe Network Dissection, a method that interprets networks by providing labels for the units of their deep visual representations. The proposed method quantifies the interpretability of CNN representations by evaluating the alignment between individual hidden units and a set of visual semantic concepts. By identifying the best alignments, units are given human interpretable labels across a range of objects, parts, scenes, textures, materials, and colors. The method reveals that deep representations are more transparent and interpretable than expected: we find that representations are significantly more interpretable than they would be under a random equivalently powerful basis. We apply the method to interpret and compare the latent representations of various network architectures trained to solve different supervised and self-supervised training tasks. We then examine factors affecting the network interpretability such as the number of the training iterations, regularizations, different initializations, and the network depth and width. Finally we show that the interpreted units can be used to provide explicit explanations of a prediction given by a CNN for an image. Our results highlight that interpretability is an important property of deep neural networks that provides new insights into their hierarchical structure.
PDF Abstract
 MS COCO
MS COCO
 Places
Places
 Caltech-101
Caltech-101
 Places205
Places205
 Caltech-256
Caltech-256
 PASCAL Context
PASCAL Context
 PASCAL-Part
PASCAL-Part
