Investigating Pretrained Language Models for Graph-to-Text Generation
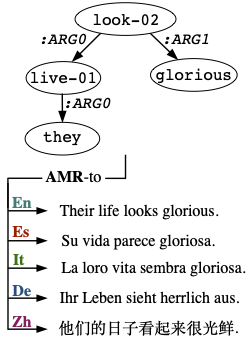
Graph-to-text generation aims to generate fluent texts from graph-based data. In this paper, we investigate two recently proposed pretrained language models (PLMs) and analyze the impact of different task-adaptive pretraining strategies for PLMs in graph-to-text generation. We present a study across three graph domains: meaning representations, Wikipedia knowledge graphs (KGs) and scientific KGs. We show that the PLMs BART and T5 achieve new state-of-the-art results and that task-adaptive pretraining strategies improve their performance even further. In particular, we report new state-of-the-art BLEU scores of 49.72 on LDC2017T10, 59.70 on WebNLG, and 25.66 on AGENDA datasets - a relative improvement of 31.8%, 4.5%, and 42.4%, respectively. In an extensive analysis, we identify possible reasons for the PLMs' success on graph-to-text tasks. We find evidence that their knowledge about true facts helps them perform well even when the input graph representation is reduced to a simple bag of node and edge labels.
PDF Abstract EMNLP (NLP4ConvAI) 2021 PDF EMNLP (NLP4ConvAI) 2021 Abstract





 DBpedia
DBpedia
 WebNLG
WebNLG
 Semantic Scholar
Semantic Scholar

