Is Someone Speaking? Exploring Long-term Temporal Features for Audio-visual Active Speaker Detection
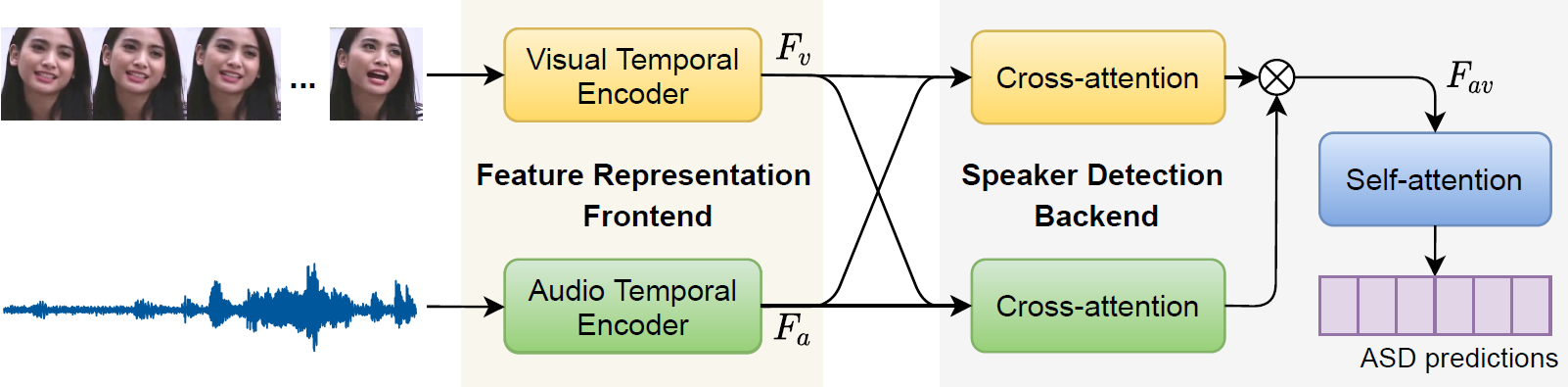
Active speaker detection (ASD) seeks to detect who is speaking in a visual scene of one or more speakers. The successful ASD depends on accurate interpretation of short-term and long-term audio and visual information, as well as audio-visual interaction. Unlike the prior work where systems make decision instantaneously using short-term features, we propose a novel framework, named TalkNet, that makes decision by taking both short-term and long-term features into consideration. TalkNet consists of audio and visual temporal encoders for feature representation, audio-visual cross-attention mechanism for inter-modality interaction, and a self-attention mechanism to capture long-term speaking evidence. The experiments demonstrate that TalkNet achieves 3.5% and 2.2% improvement over the state-of-the-art systems on the AVA-ActiveSpeaker dataset and Columbia ASD dataset, respectively. Code has been made available at: https://github.com/TaoRuijie/TalkNet_ASD.
PDF Abstract

 VoxCeleb2
VoxCeleb2
