Iterative Amortized Policy Optimization
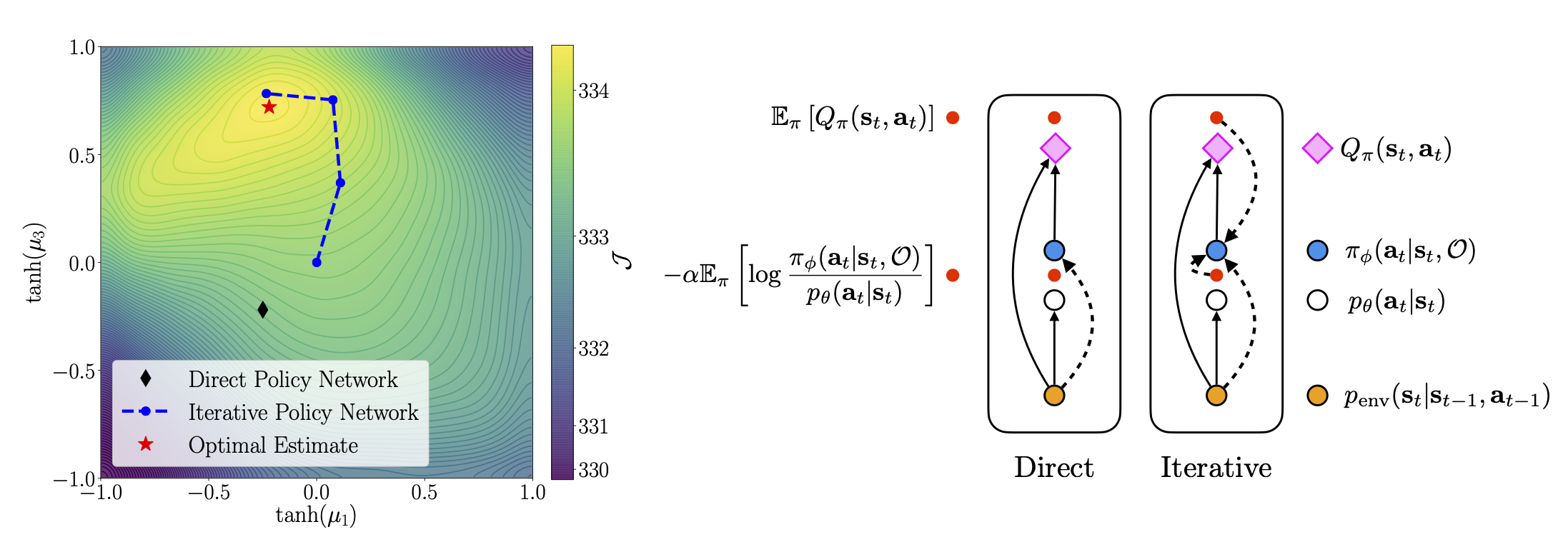
Policy networks are a central feature of deep reinforcement learning (RL) algorithms for continuous control, enabling the estimation and sampling of high-value actions. From the variational inference perspective on RL, policy networks, when employed with entropy or KL regularization, are a form of amortized optimization, optimizing network parameters rather than the policy distributions directly. However, this direct amortized mapping can empirically yield suboptimal policy estimates. Given this perspective, we consider the more flexible class of iterative amortized optimizers. We demonstrate that the resulting technique, iterative amortized policy optimization, yields performance improvements over conventional direct amortization methods on benchmark continuous control tasks.
PDF Abstract NeurIPS 2021 PDF NeurIPS 2021 Abstract

 MuJoCo
MuJoCo
 OpenAI Gym
OpenAI Gym
