Joint-Modal Label Denoising for Weakly-Supervised Audio-Visual Video Parsing
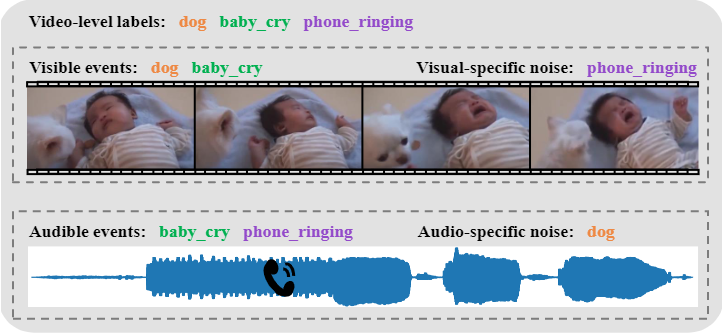
This paper focuses on the weakly-supervised audio-visual video parsing task, which aims to recognize all events belonging to each modality and localize their temporal boundaries. This task is challenging because only overall labels indicating the video events are provided for training. However, an event might be labeled but not appear in one of the modalities, which results in a modality-specific noisy label problem. In this work, we propose a training strategy to identify and remove modality-specific noisy labels dynamically. It is motivated by two key observations: 1) networks tend to learn clean samples first; and 2) a labeled event would appear in at least one modality. Specifically, we sort the losses of all instances within a mini-batch individually in each modality, and then select noisy samples according to the relationships between intra-modal and inter-modal losses. Besides, we also propose a simple but valid noise ratio estimation method by calculating the proportion of instances whose confidence is below a preset threshold. Our method makes large improvements over the previous state of the arts (e.g. from 60.0\% to 63.8\% in segment-level visual metric), which demonstrates the effectiveness of our approach. Code and trained models are publicly available at \url{https://github.com/MCG-NJU/JoMoLD}.
PDF Abstract


