Joint Pre-Training with Speech and Bilingual Text for Direct Speech to Speech Translation
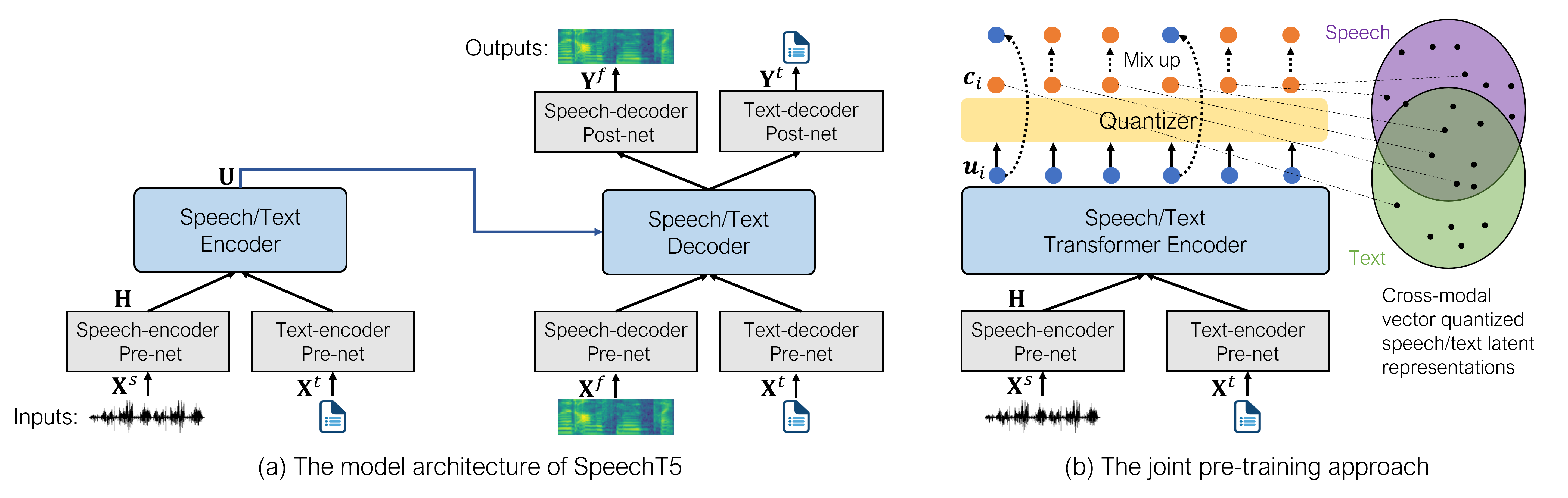
Direct speech-to-speech translation (S2ST) is an attractive research topic with many advantages compared to cascaded S2ST. However, direct S2ST suffers from the data scarcity problem because the corpora from speech of the source language to speech of the target language are very rare. To address this issue, we propose in this paper a Speech2S model, which is jointly pre-trained with unpaired speech and bilingual text data for direct speech-to-speech translation tasks. By effectively leveraging the paired text data, Speech2S is capable of modeling the cross-lingual speech conversion from source to target language. We verify the performance of the proposed Speech2S on Europarl-ST and VoxPopuli datasets. Experimental results demonstrate that Speech2S gets an improvement of about 5 BLEU scores compared to encoder-only pre-training models, and achieves a competitive or even better performance than existing state-of-the-art models1.
PDF Abstract

