
Just Ask: Learning to Answer Questions from Millions of Narrated Videos
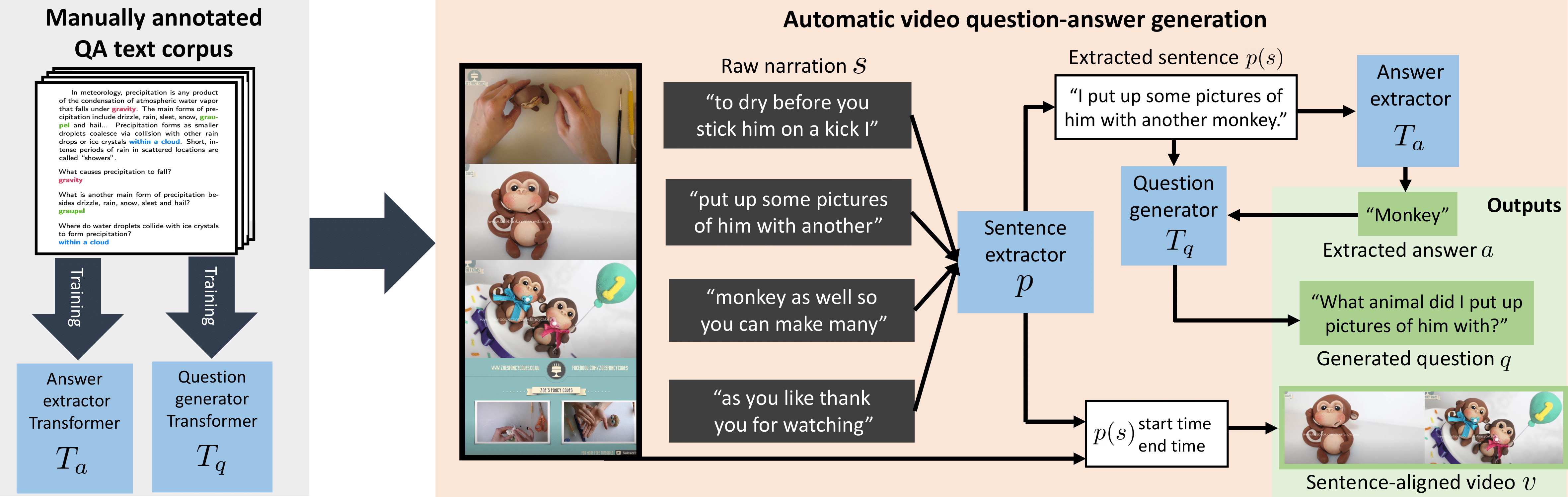
Recent methods for visual question answering rely on large-scale annotated datasets. Manual annotation of questions and answers for videos, however, is tedious, expensive and prevents scalability. In this work, we propose to avoid manual annotation and generate a large-scale training dataset for video question answering making use of automatic cross-modal supervision. We leverage a question generation transformer trained on text data and use it to generate question-answer pairs from transcribed video narrations. Given narrated videos, we then automatically generate the HowToVQA69M dataset with 69M video-question-answer triplets. To handle the open vocabulary of diverse answers in this dataset, we propose a training procedure based on a contrastive loss between a video-question multi-modal transformer and an answer transformer. We introduce the zero-shot VideoQA task and show excellent results, in particular for rare answers. Furthermore, we demonstrate our method to significantly outperform the state of the art on MSRVTT-QA, MSVD-QA, ActivityNet-QA and How2QA. Finally, for a detailed evaluation we introduce iVQA, a new VideoQA dataset with reduced language biases and high-quality redundant manual annotations. Our code, datasets and trained models are available at https://antoyang.github.io/just-ask.html.
PDF Abstract ICCV 2021 PDF ICCV 2021 AbstractCode





Datasets
Introduced in the Paper:
 iVQA
iVQA
 HowToVQA69M
HowToVQA69M
Used in the Paper:
 HowTo100M
HowTo100M
 ActivityNet-QA
MSRVTT-QA
MSVD-QA
ActivityNet-QA
MSRVTT-QA
MSVD-QA
 How2QA
How2QA

