Kafnets: kernel-based non-parametric activation functions for neural networks
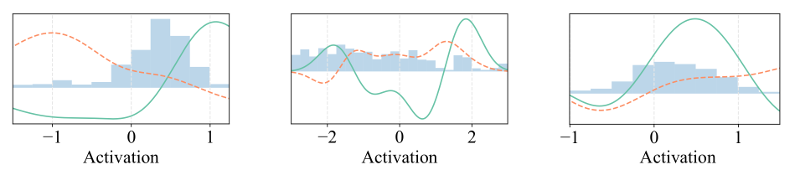
Neural networks are generally built by interleaving (adaptable) linear layers with (fixed) nonlinear activation functions. To increase their flexibility, several authors have proposed methods for adapting the activation functions themselves, endowing them with varying degrees of flexibility. None of these approaches, however, have gained wide acceptance in practice, and research in this topic remains open. In this paper, we introduce a novel family of flexible activation functions that are based on an inexpensive kernel expansion at every neuron. Leveraging over several properties of kernel-based models, we propose multiple variations for designing and initializing these kernel activation functions (KAFs), including a multidimensional scheme allowing to nonlinearly combine information from different paths in the network. The resulting KAFs can approximate any mapping defined over a subset of the real line, either convex or nonconvex. Furthermore, they are smooth over their entire domain, linear in their parameters, and they can be regularized using any known scheme, including the use of $\ell_1$ penalties to enforce sparseness. To the best of our knowledge, no other known model satisfies all these properties simultaneously. In addition, we provide a relatively complete overview on alternative techniques for adapting the activation functions, which is currently lacking in the literature. A large set of experiments validates our proposal.
PDF Abstract
