Knowledge Elicitation via Sequential Probabilistic Inference for High-Dimensional Prediction
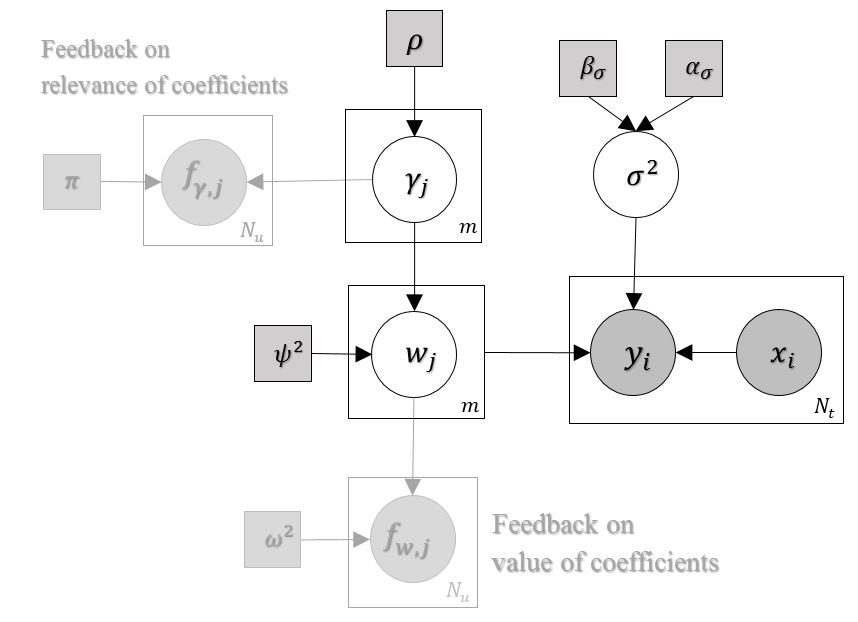
Prediction in a small-sized sample with a large number of covariates, the "small n, large p" problem, is challenging. This setting is encountered in multiple applications, such as precision medicine, where obtaining additional samples can be extremely costly or even impossible, and extensive research effort has recently been dedicated to finding principled solutions for accurate prediction. However, a valuable source of additional information, domain experts, has not yet been efficiently exploited. We formulate knowledge elicitation generally as a probabilistic inference process, where expert knowledge is sequentially queried to improve predictions. In the specific case of sparse linear regression, where we assume the expert has knowledge about the values of the regression coefficients or about the relevance of the features, we propose an algorithm and computational approximation for fast and efficient interaction, which sequentially identifies the most informative features on which to query expert knowledge. Evaluations of our method in experiments with simulated and real users show improved prediction accuracy already with a small effort from the expert.
PDF Abstract
