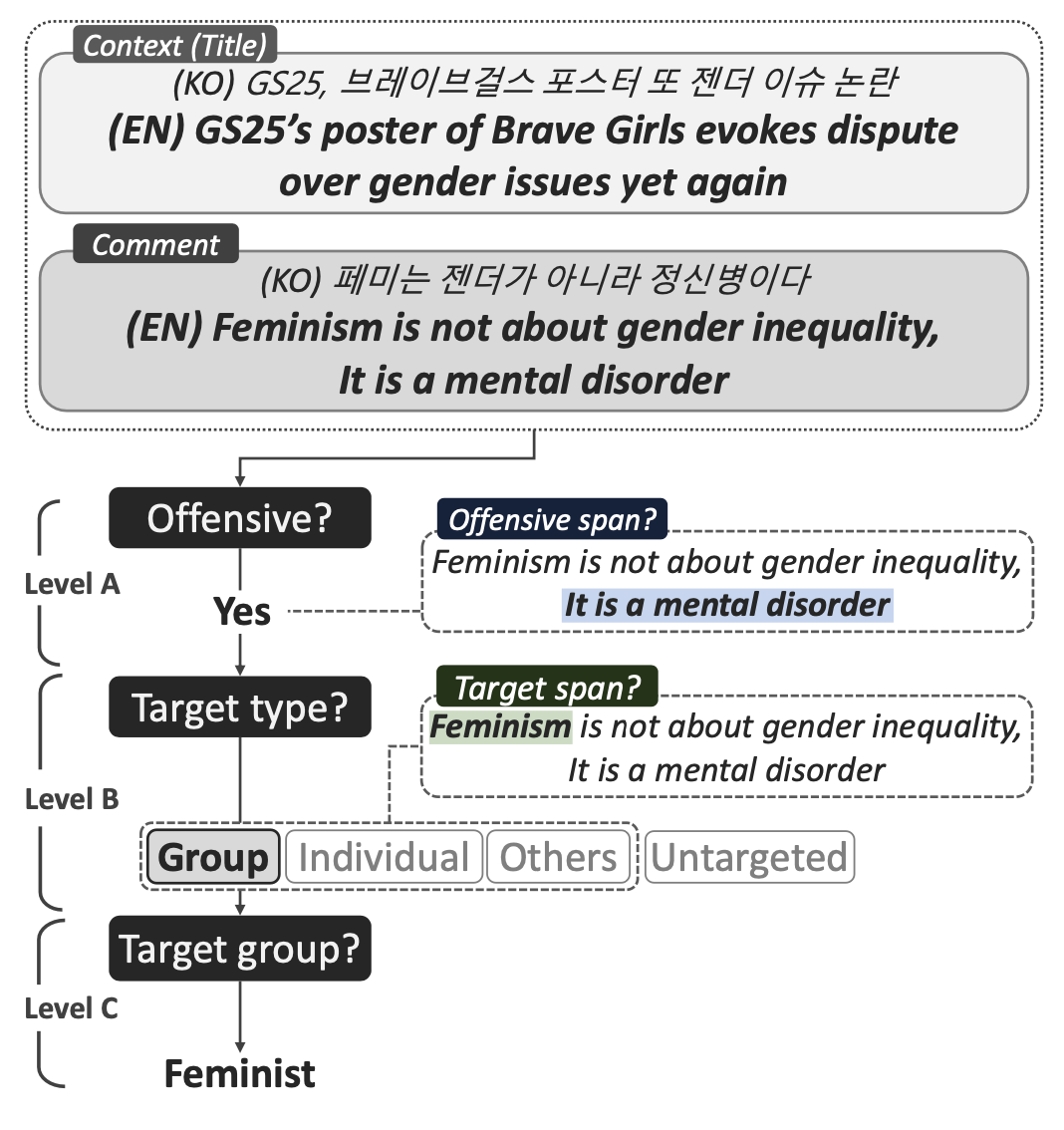
KOLD: Korean Offensive Language Dataset
Recent directions for offensive language detection are hierarchical modeling, identifying the type and the target of offensive language, and interpretability with offensive span annotation and prediction. These improvements are focused on English and do not transfer well to other languages because of cultural and linguistic differences. In this paper, we present the Korean Offensive Language Dataset (KOLD) comprising 40,429 comments, which are annotated hierarchically with the type and the target of offensive language, accompanied by annotations of the corresponding text spans. We collect the comments from NAVER news and YouTube platform and provide the titles of the articles and videos as the context information for the annotation process. We use these annotated comments as training data for Korean BERT and RoBERTa models and find that they are effective at offensiveness detection, target classification, and target span detection while having room for improvement for target group classification and offensive span detection. We discover that the target group distribution differs drastically from the existing English datasets, and observe that providing the context information improves the model performance in offensiveness detection (+0.3), target classification (+1.5), and target group classification (+13.1). We publicly release the dataset and baseline models.
PDF Abstract
 OLID
OLID
