Language-Agnostic Syllabification with Neural Sequence Labeling
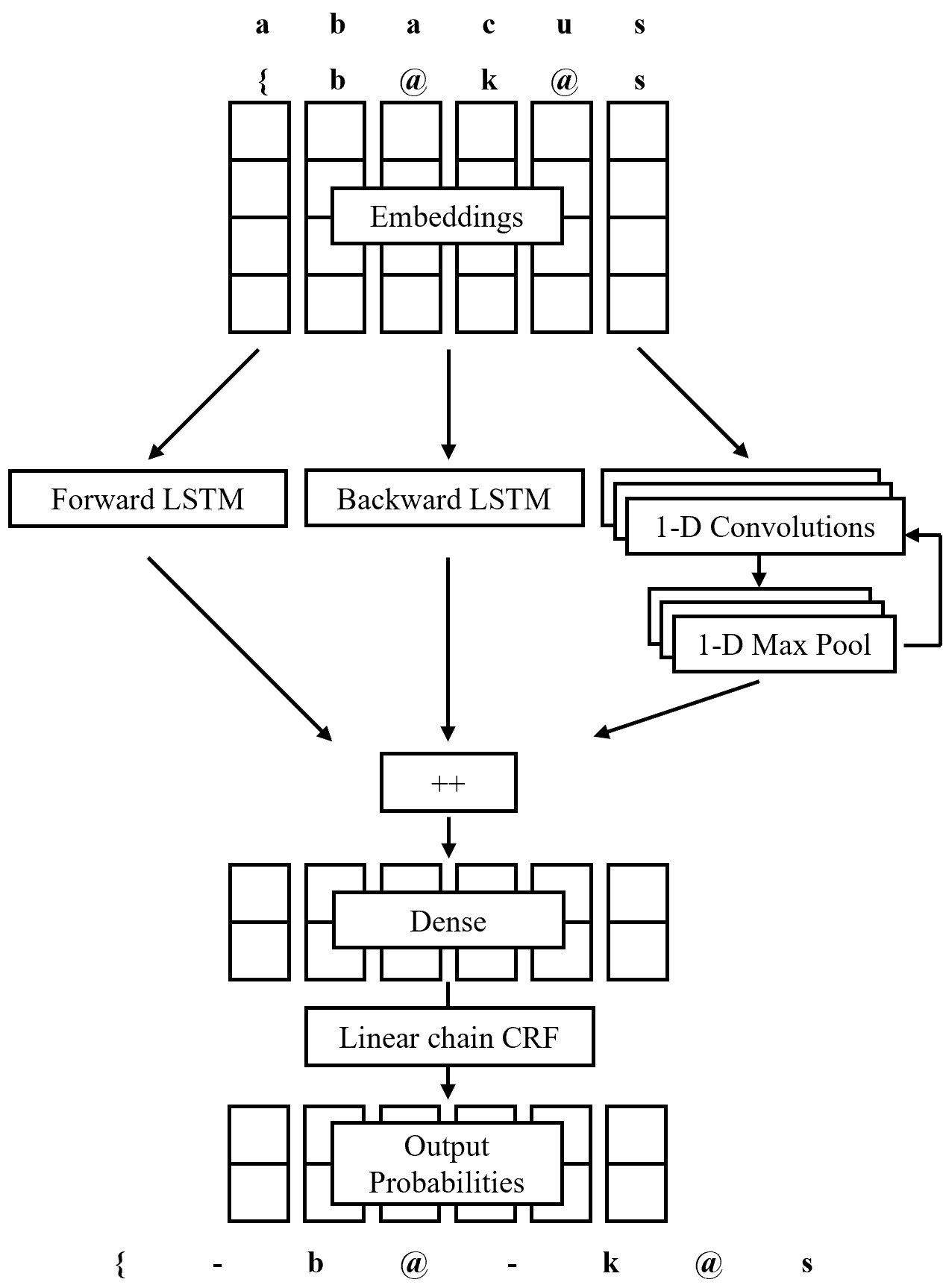
The identification of syllables within phonetic sequences is known as syllabification. This task is thought to play an important role in natural language understanding, speech production, and the development of speech recognition systems. The concept of the syllable is cross-linguistic, though formal definitions are rarely agreed upon, even within a language. In response, data-driven syllabification methods have been developed to learn from syllabified examples. These methods often employ classical machine learning sequence labeling models. In recent years, recurrence-based neural networks have been shown to perform increasingly well for sequence labeling tasks such as named entity recognition (NER), part of speech (POS) tagging, and chunking. We present a novel approach to the syllabification problem which leverages modern neural network techniques. Our network is constructed with long short-term memory (LSTM) cells, a convolutional component, and a conditional random field (CRF) output layer. Existing syllabification approaches are rarely evaluated across multiple language families. To demonstrate cross-linguistic generalizability, we show that the network is competitive with state of the art systems in syllabifying English, Dutch, Italian, French, Manipuri, and Basque datasets.
PDF Abstract



