SAM: Squeeze-and-Mimic Networks for Conditional Visual Driving Policy Learning
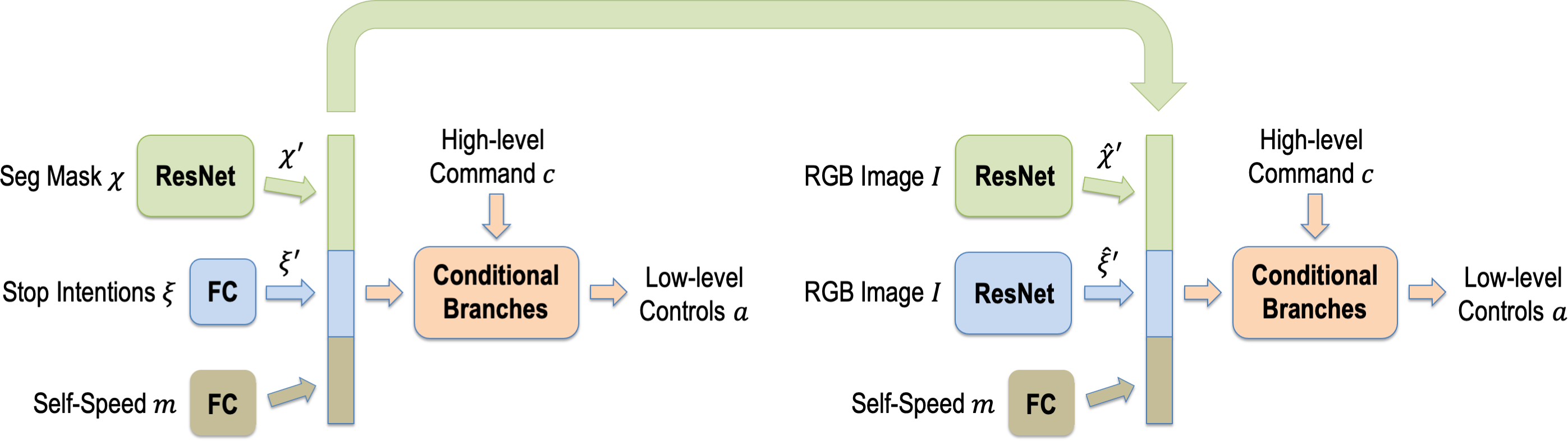
We describe a policy learning approach to map visual inputs to driving controls conditioned on turning command that leverages side tasks on semantics and object affordances via a learned representation trained for driving. To learn this representation, we train a squeeze network to drive using annotations for the side task as input. This representation encodes the driving-relevant information associated with the side task while ideally throwing out side task-relevant but driving-irrelevant nuisances. We then train a mimic network to drive using only images as input and use the squeeze network's latent representation to supervise the mimic network via a mimicking loss. Notably, we do not aim to achieve the side task nor to learn features for it; instead, we aim to learn, via the mimicking loss, a representation of the side task annotations directly useful for driving. We test our approach using the CARLA simulator. In addition, we introduce a more challenging but realistic evaluation protocol that considers a run that reaches the destination successful only if it does not violate common traffic rules. A video summarizing this work is available at https://youtu.be/ipKAMzmJpMs , and code is available at https://github.com/twsq/sam-driving .
PDF Abstract
 CARLA
CARLA
