Learning 3D Representations from 2D Pre-trained Models via Image-to-Point Masked Autoencoders
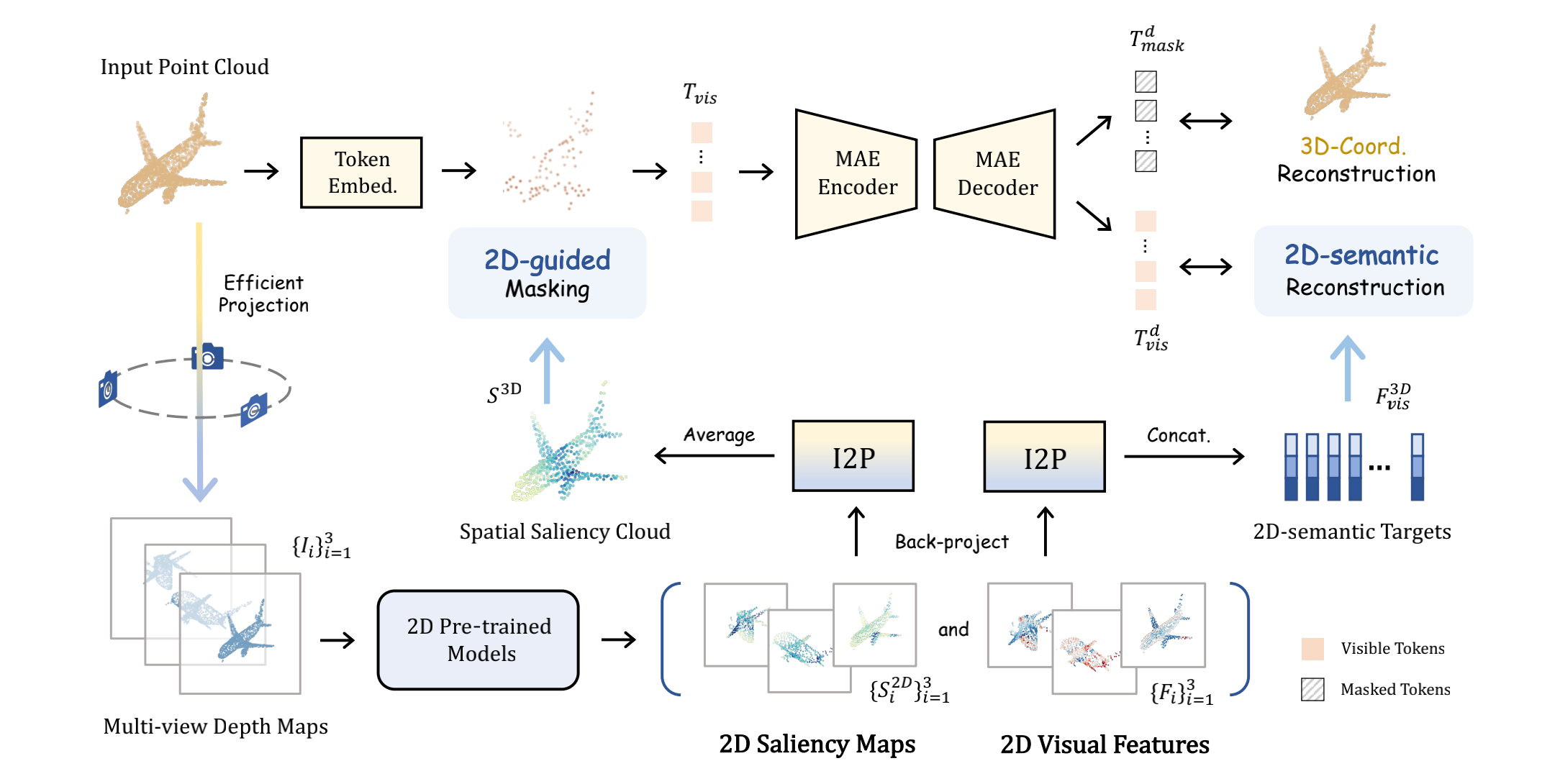
Pre-training by numerous image data has become de-facto for robust 2D representations. In contrast, due to the expensive data acquisition and annotation, a paucity of large-scale 3D datasets severely hinders the learning for high-quality 3D features. In this paper, we propose an alternative to obtain superior 3D representations from 2D pre-trained models via Image-to-Point Masked Autoencoders, named as I2P-MAE. By self-supervised pre-training, we leverage the well learned 2D knowledge to guide 3D masked autoencoding, which reconstructs the masked point tokens with an encoder-decoder architecture. Specifically, we first utilize off-the-shelf 2D models to extract the multi-view visual features of the input point cloud, and then conduct two types of image-to-point learning schemes on top. For one, we introduce a 2D-guided masking strategy that maintains semantically important point tokens to be visible for the encoder. Compared to random masking, the network can better concentrate on significant 3D structures and recover the masked tokens from key spatial cues. For another, we enforce these visible tokens to reconstruct the corresponding multi-view 2D features after the decoder. This enables the network to effectively inherit high-level 2D semantics learned from rich image data for discriminative 3D modeling. Aided by our image-to-point pre-training, the frozen I2P-MAE, without any fine-tuning, achieves 93.4% accuracy for linear SVM on ModelNet40, competitive to the fully trained results of existing methods. By further fine-tuning on on ScanObjectNN's hardest split, I2P-MAE attains the state-of-the-art 90.11% accuracy, +3.68% to the second-best, demonstrating superior transferable capacity. Code will be available at https://github.com/ZrrSkywalker/I2P-MAE.
PDF Abstract CVPR 2023 PDF CVPR 2023 AbstractCode



Datasets
 ShapeNet
ShapeNet
 ModelNet
ModelNet
 ScanObjectNN
ScanObjectNN
Results from the Paper
 Ranked #2 on
3D Point Cloud Linear Classification
on ModelNet40
(using extra training data)
Ranked #2 on
3D Point Cloud Linear Classification
on ModelNet40
(using extra training data)
