Learning Causal Models Online
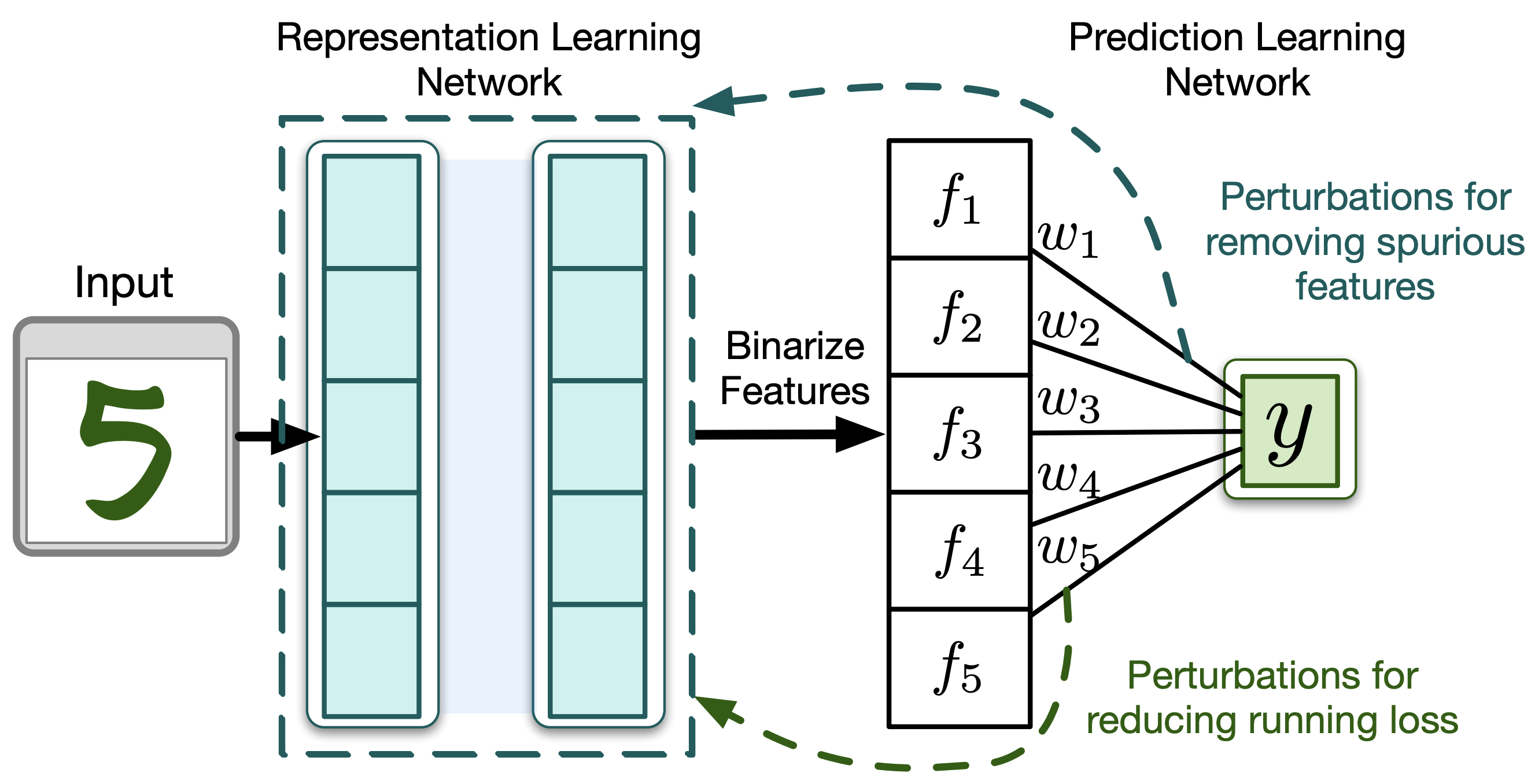
Predictive models -- learned from observational data not covering the complete data distribution -- can rely on spurious correlations in the data for making predictions. These correlations make the models brittle and hinder generalization. One solution for achieving strong generalization is to incorporate causal structures in the models; such structures constrain learning by ignoring correlations that contradict them. However, learning these structures is a hard problem in itself. Moreover, it's not clear how to incorporate the machinery of causality with online continual learning. In this work, we take an indirect approach to discovering causal models. Instead of searching for the true causal model directly, we propose an online algorithm that continually detects and removes spurious features. Our algorithm works on the idea that the correlation of a spurious feature with a target is not constant over-time. As a result, the weight associated with that feature is constantly changing. We show that by continually removing such features, our method converges to solutions that have strong generalization. Moreover, our method combined with random search can also discover non-spurious features from raw sensory data. Finally, our work highlights that the information present in the temporal structure of the problem -- destroyed by shuffling the data -- is essential for detecting spurious features online.
PDF Abstract

