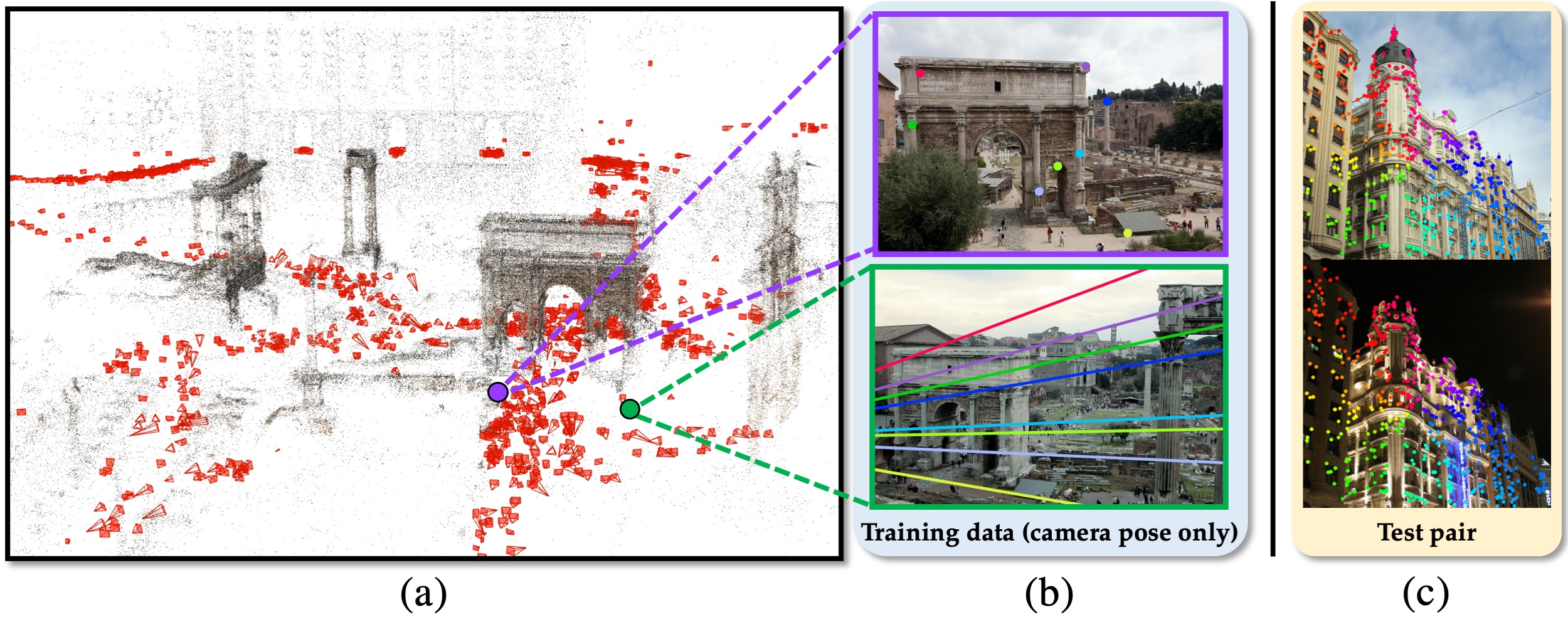
Learning Feature Descriptors using Camera Pose Supervision
Recent research on learned visual descriptors has shown promising improvements in correspondence estimation, a key component of many 3D vision tasks. However, existing descriptor learning frameworks typically require ground-truth correspondences between feature points for training, which are challenging to acquire at scale. In this paper we propose a novel weakly-supervised framework that can learn feature descriptors solely from relative camera poses between images. To do so, we devise both a new loss function that exploits the epipolar constraint given by camera poses, and a new model architecture that makes the whole pipeline differentiable and efficient. Because we no longer need pixel-level ground-truth correspondences, our framework opens up the possibility of training on much larger and more diverse datasets for better and unbiased descriptors. We call the resulting descriptors CAmera Pose Supervised, or CAPS, descriptors. Though trained with weak supervision, CAPS descriptors outperform even prior fully-supervised descriptors and achieve state-of-the-art performance on a variety of geometric tasks. Project Page: https://qianqianwang68.github.io/CAPS/
PDF Abstract ECCV 2020 PDF ECCV 2020 Abstract
 ScanNet
ScanNet
 HPatches
HPatches
 MegaDepth
MegaDepth
