Learning Ordered Representations with Nested Dropout
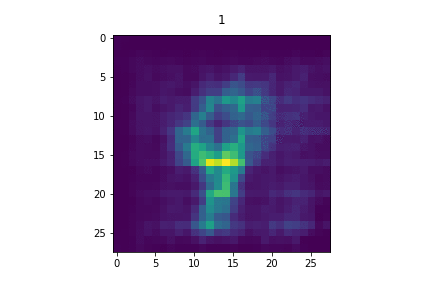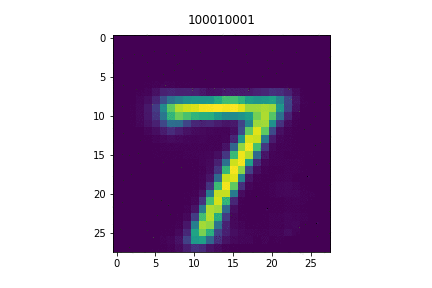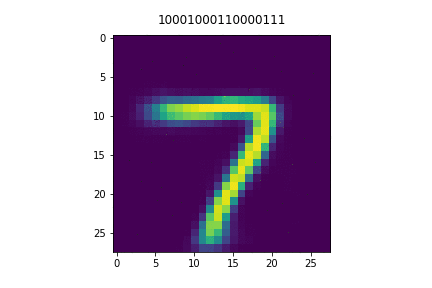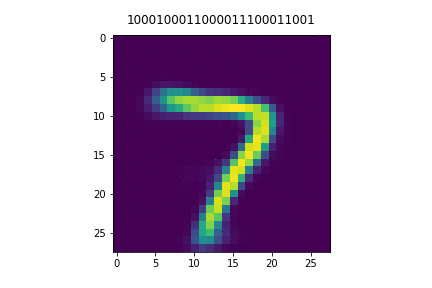
In this paper, we study ordered representations of data in which different dimensions have different degrees of importance. To learn these representations we introduce nested dropout, a procedure for stochastically removing coherent nested sets of hidden units in a neural network. We first present a sequence of theoretical results in the simple case of a semi-linear autoencoder. We rigorously show that the application of nested dropout enforces identifiability of the units, which leads to an exact equivalence with PCA. We then extend the algorithm to deep models and demonstrate the relevance of ordered representations to a number of applications. Specifically, we use the ordered property of the learned codes to construct hash-based data structures that permit very fast retrieval, achieving retrieval in time logarithmic in the database size and independent of the dimensionality of the representation. This allows codes that are hundreds of times longer than currently feasible for retrieval. We therefore avoid the diminished quality associated with short codes, while still performing retrieval that is competitive in speed with existing methods. We also show that ordered representations are a promising way to learn adaptive compression for efficient online data reconstruction.
PDF Abstract

