Learning Rate Dropout
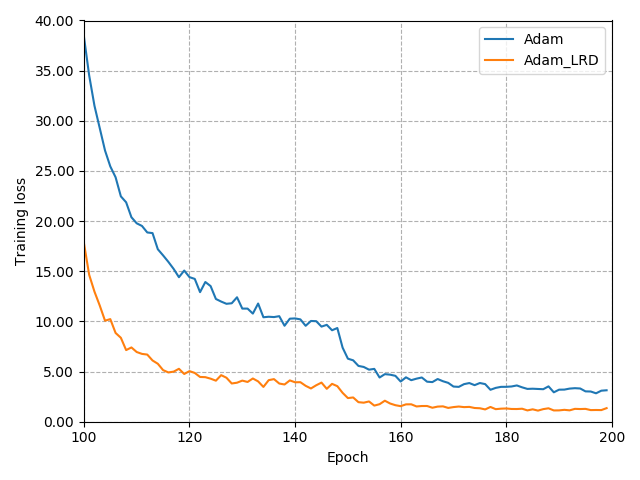
The performance of a deep neural network is highly dependent on its training, and finding better local optimal solutions is the goal of many optimization algorithms. However, existing optimization algorithms show a preference for descent paths that converge slowly and do not seek to avoid bad local optima. In this work, we propose Learning Rate Dropout (LRD), a simple gradient descent technique for training related to coordinate descent. LRD empirically aids the optimizer to actively explore in the parameter space by randomly setting some learning rates to zero; at each iteration, only parameters whose learning rate is not 0 are updated. As the learning rate of different parameters is dropped, the optimizer will sample a new loss descent path for the current update. The uncertainty of the descent path helps the model avoid saddle points and bad local minima. Experiments show that LRD is surprisingly effective in accelerating training while preventing overfitting.
PDF Abstract
 CIFAR-10
CIFAR-10
 CIFAR-100
CIFAR-100
