Learning Sparse & Ternary Neural Networks with Entropy-Constrained Trained Ternarization (EC2T)
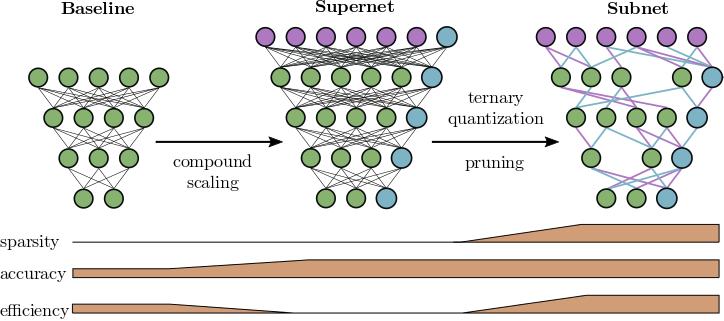
Deep neural networks (DNN) have shown remarkable success in a variety of machine learning applications. The capacity of these models (i.e., number of parameters), endows them with expressive power and allows them to reach the desired performance. In recent years, there is an increasing interest in deploying DNNs to resource-constrained devices (i.e., mobile devices) with limited energy, memory, and computational budget. To address this problem, we propose Entropy-Constrained Trained Ternarization (EC2T), a general framework to create sparse and ternary neural networks which are efficient in terms of storage (e.g., at most two binary-masks and two full-precision values are required to save a weight matrix) and computation (e.g., MAC operations are reduced to a few accumulations plus two multiplications). This approach consists of two steps. First, a super-network is created by scaling the dimensions of a pre-trained model (i.e., its width and depth). Subsequently, this super-network is simultaneously pruned (using an entropy constraint) and quantized (that is, ternary values are assigned layer-wise) in a training process, resulting in a sparse and ternary network representation. We validate the proposed approach in CIFAR-10, CIFAR-100, and ImageNet datasets, showing its effectiveness in image classification tasks.
PDF Abstract

