Learning to compress and search visual data in large-scale systems
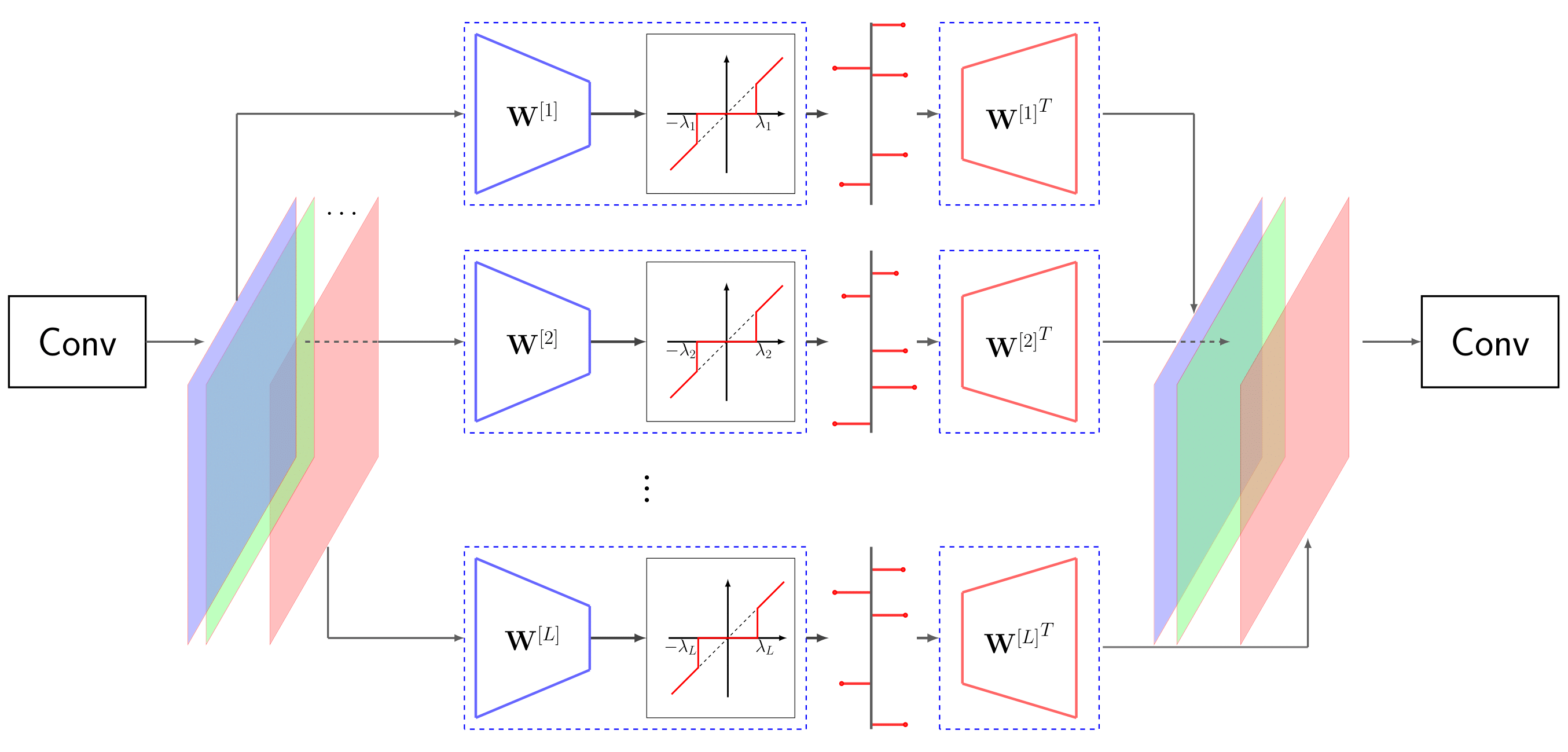
The problem of high-dimensional and large-scale representation of visual data is addressed from an unsupervised learning perspective. The emphasis is put on discrete representations, where the description length can be measured in bits and hence the model capacity can be controlled. The algorithmic infrastructure is developed based on the synthesis and analysis prior models whose rate-distortion properties, as well as capacity vs. sample complexity trade-offs are carefully optimized. These models are then extended to multi-layers, namely the RRQ and the ML-STC frameworks, where the latter is further evolved as a powerful deep neural network architecture with fast and sample-efficient training and discrete representations. For the developed algorithms, three important applications are developed. First, the problem of large-scale similarity search in retrieval systems is addressed, where a double-stage solution is proposed leading to faster query times and shorter database storage. Second, the problem of learned image compression is targeted, where the proposed models can capture more redundancies from the training images than the conventional compression codecs. Finally, the proposed algorithms are used to solve ill-posed inverse problems. In particular, the problems of image denoising and compressive sensing are addressed with promising results.
PDF Abstract



