Learning to Learn Better for Video Object Segmentation
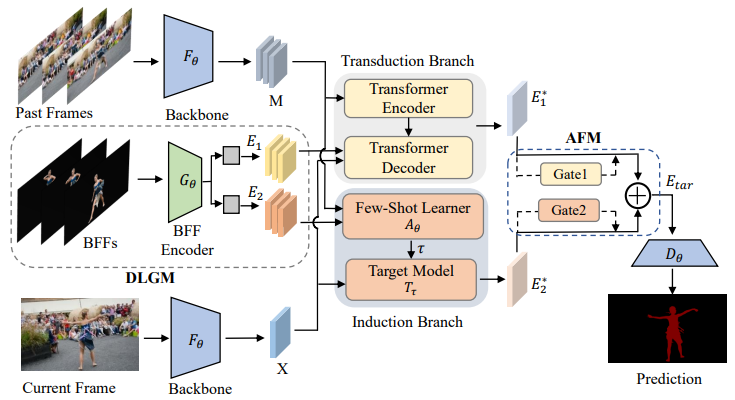
Recently, the joint learning framework (JOINT) integrates matching based transductive reasoning and online inductive learning to achieve accurate and robust semi-supervised video object segmentation (SVOS). However, using the mask embedding as the label to guide the generation of target features in the two branches may result in inadequate target representation and degrade the performance. Besides, how to reasonably fuse the target features in the two different branches rather than simply adding them together to avoid the adverse effect of one dominant branch has not been investigated. In this paper, we propose a novel framework that emphasizes Learning to Learn Better (LLB) target features for SVOS, termed LLB, where we design the discriminative label generation module (DLGM) and the adaptive fusion module to address these issues. Technically, the DLGM takes the background-filtered frame instead of the target mask as input and adopts a lightweight encoder to generate the target features, which serves as the label of the online few-shot learner and the value of the decoder in the transformer to guide the two branches to learn more discriminative target representation. The adaptive fusion module maintains a learnable gate for each branch, which reweighs the element-wise feature representation and allows an adaptive amount of target information in each branch flowing to the fused target feature, thus preventing one branch from being dominant and making the target feature more robust to distractor. Extensive experiments on public benchmarks show that our proposed LLB method achieves state-of-the-art performance.
PDF Abstract




 DAVIS 2017
DAVIS 2017
