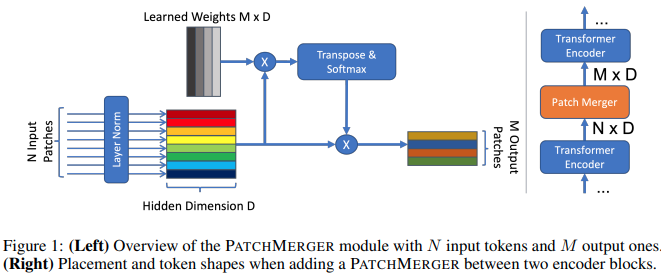
Learning to Merge Tokens in Vision Transformers
Transformers are widely applied to solve natural language understanding and computer vision tasks. While scaling up these architectures leads to improved performance, it often comes at the expense of much higher computational costs. In order for large-scale models to remain practical in real-world systems, there is a need for reducing their computational overhead. In this work, we present the PatchMerger, a simple module that reduces the number of patches or tokens the network has to process by merging them between two consecutive intermediate layers. We show that the PatchMerger achieves a significant speedup across various model sizes while matching the original performance both upstream and downstream after fine-tuning.
PDF Abstract

 ImageNet
ImageNet
