Learning to rank for censored survival data
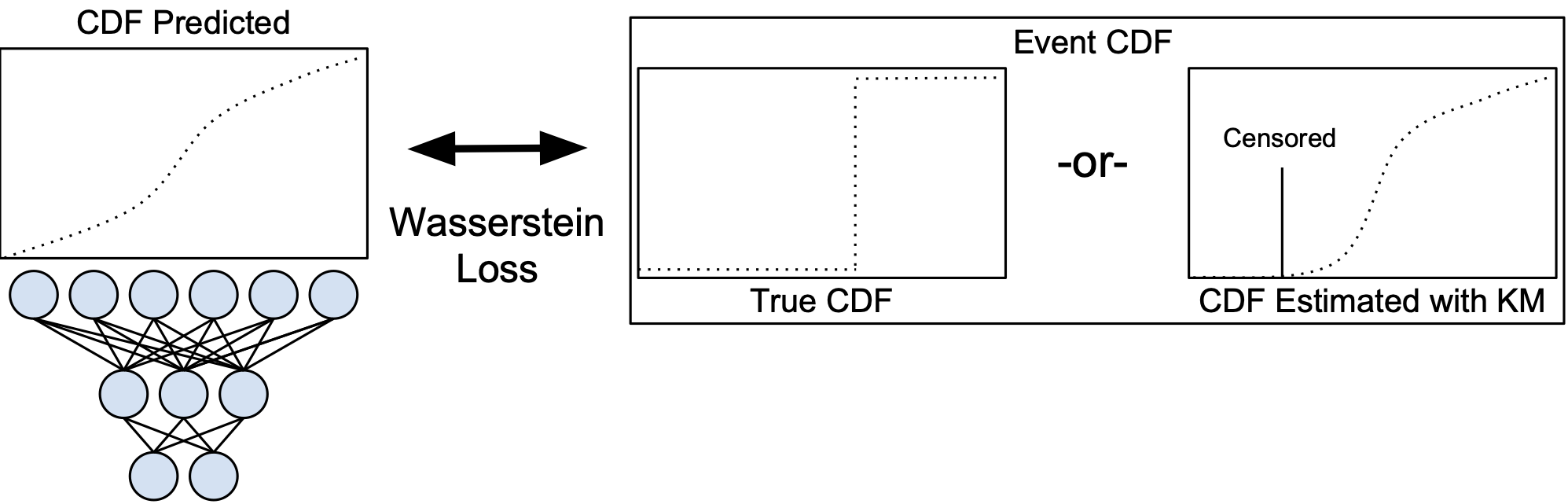
Survival analysis is a type of semi-supervised ranking task where the target output (the survival time) is often right-censored. Utilizing this information is a challenge because it is not obvious how to correctly incorporate these censored examples into a model. We study how three categories of loss functions, namely partial likelihood methods, rank methods, and our classification method based on a Wasserstein metric (WM) and the non-parametric Kaplan Meier estimate of the probability density to impute the labels of censored examples, can take advantage of this information. The proposed method allows us to have a model that predict the probability distribution of an event. If a clinician had access to the detailed probability of an event over time this would help in treatment planning. For example, determining if the risk of kidney graft rejection is constant or peaked after some time. Also, we demonstrate that this approach directly optimizes the expected C-index which is the most common evaluation metric for ranking survival models.
PDF Abstract


