Learning to Select Bi-Aspect Information for Document-Scale Text Content Manipulation
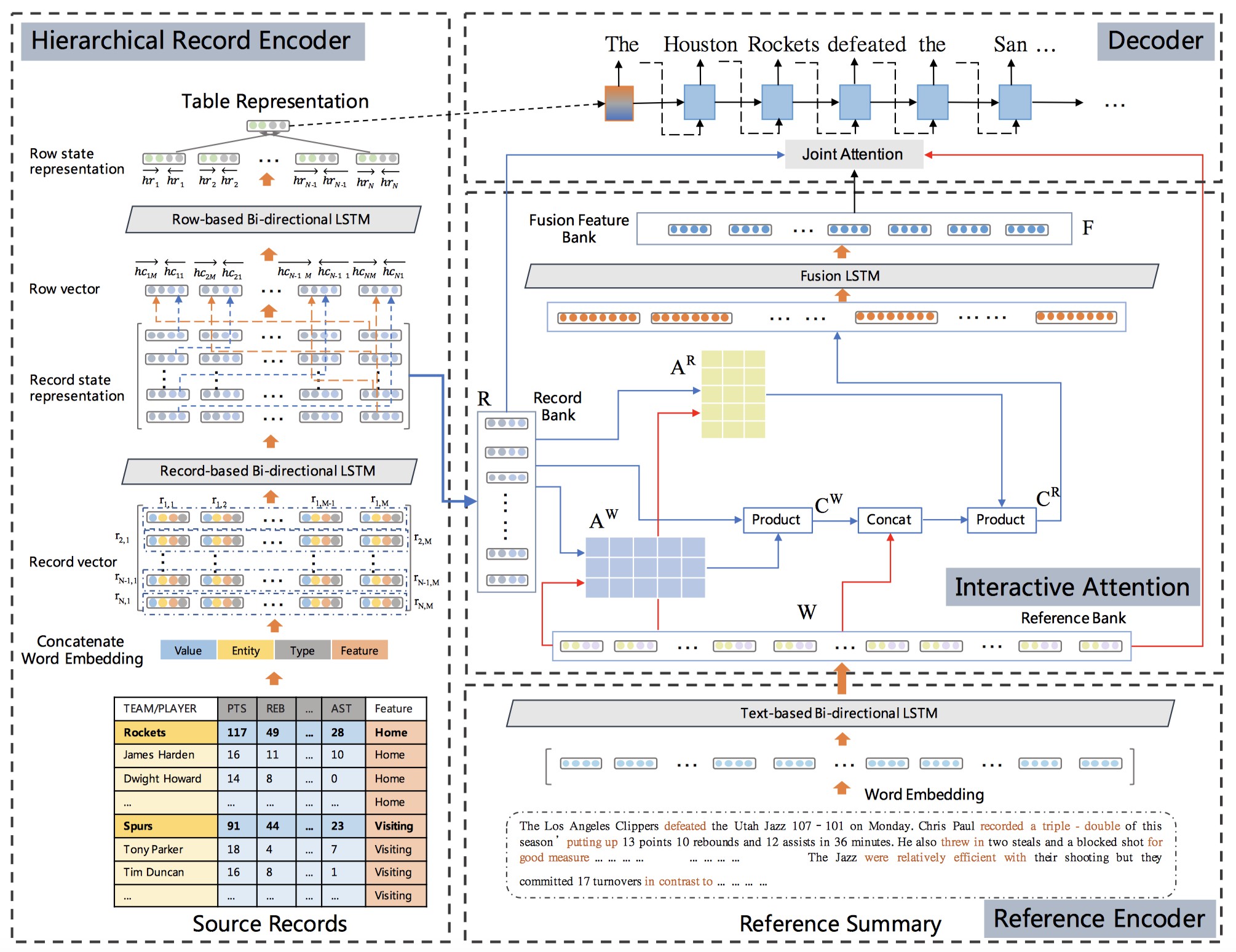
In this paper, we focus on a new practical task, document-scale text content manipulation, which is the opposite of text style transfer and aims to preserve text styles while altering the content. In detail, the input is a set of structured records and a reference text for describing another recordset. The output is a summary that accurately describes the partial content in the source recordset with the same writing style of the reference. The task is unsupervised due to lack of parallel data, and is challenging to select suitable records and style words from bi-aspect inputs respectively and generate a high-fidelity long document. To tackle those problems, we first build a dataset based on a basketball game report corpus as our testbed, and present an unsupervised neural model with interactive attention mechanism, which is used for learning the semantic relationship between records and reference texts to achieve better content transfer and better style preservation. In addition, we also explore the effectiveness of the back-translation in our task for constructing some pseudo-training pairs. Empirical results show superiority of our approaches over competitive methods, and the models also yield a new state-of-the-art result on a sentence-level dataset.
PDF Abstract


