Learning to Weight Samples for Dynamic Early-exiting Networks
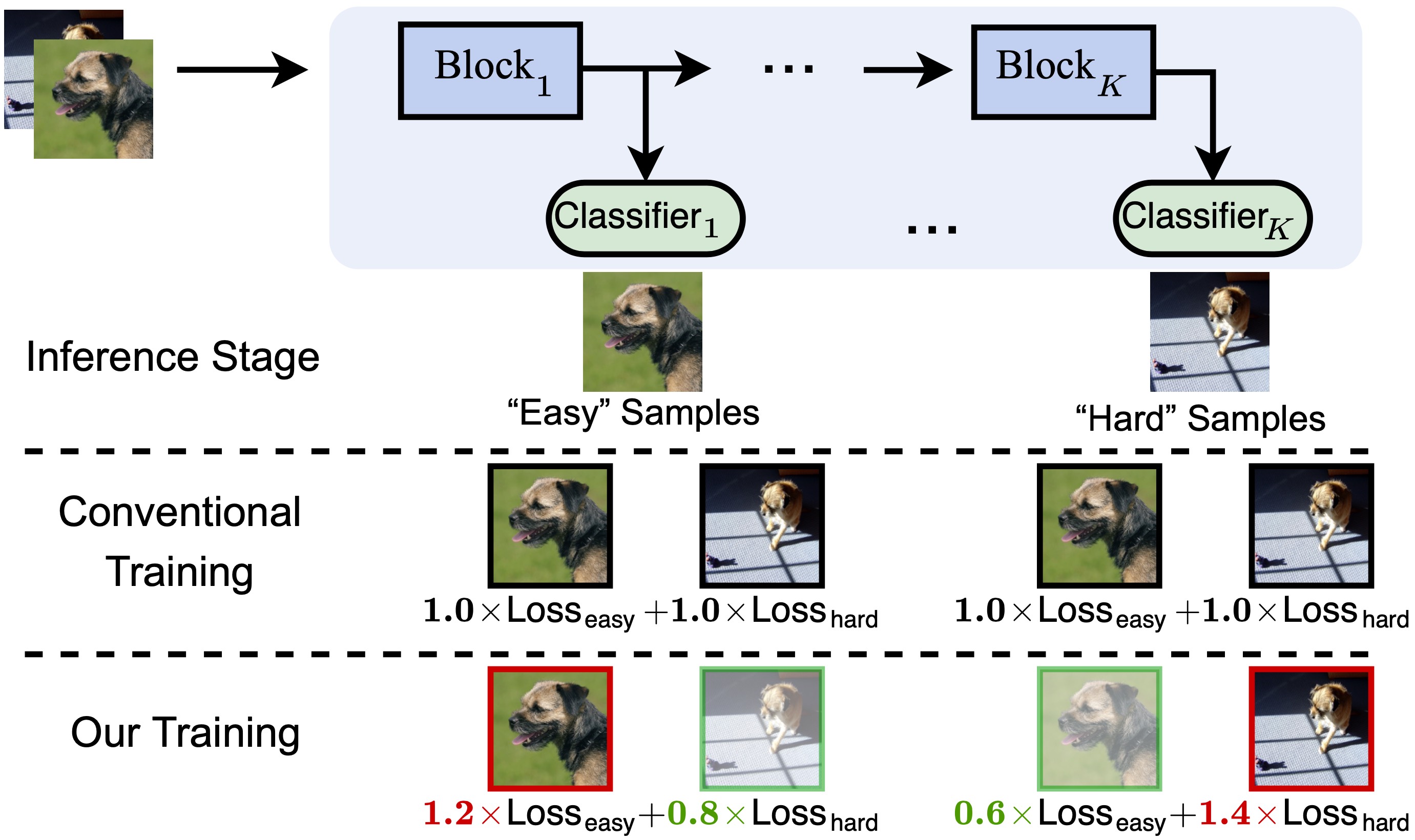
Early exiting is an effective paradigm for improving the inference efficiency of deep networks. By constructing classifiers with varying resource demands (the exits), such networks allow easy samples to be output at early exits, removing the need for executing deeper layers. While existing works mainly focus on the architectural design of multi-exit networks, the training strategies for such models are largely left unexplored. The current state-of-the-art models treat all samples the same during training. However, the early-exiting behavior during testing has been ignored, leading to a gap between training and testing. In this paper, we propose to bridge this gap by sample weighting. Intuitively, easy samples, which generally exit early in the network during inference, should contribute more to training early classifiers. The training of hard samples (mostly exit from deeper layers), however, should be emphasized by the late classifiers. Our work proposes to adopt a weight prediction network to weight the loss of different training samples at each exit. This weight prediction network and the backbone model are jointly optimized under a meta-learning framework with a novel optimization objective. By bringing the adaptive behavior during inference into the training phase, we show that the proposed weighting mechanism consistently improves the trade-off between classification accuracy and inference efficiency. Code is available at https://github.com/LeapLabTHU/L2W-DEN.
PDF Abstract

 CIFAR-10
CIFAR-10
 ImageNet
ImageNet
 CIFAR-100
CIFAR-100
