Learning Visually-Grounded Semantics from Contrastive Adversarial Samples
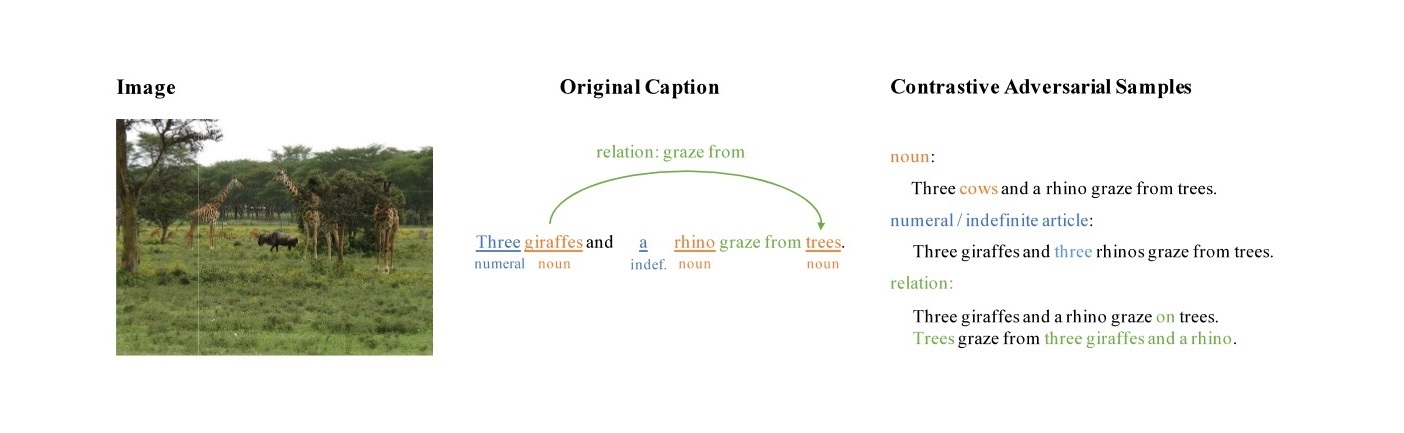
We study the problem of grounding distributional representations of texts on the visual domain, namely visual-semantic embeddings (VSE for short). Begin with an insightful adversarial attack on VSE embeddings, we show the limitation of current frameworks and image-text datasets (e.g., MS-COCO) both quantitatively and qualitatively. The large gap between the number of possible constitutions of real-world semantics and the size of parallel data, to a large extent, restricts the model to establish the link between textual semantics and visual concepts. We alleviate this problem by augmenting the MS-COCO image captioning datasets with textual contrastive adversarial samples. These samples are synthesized using linguistic rules and the WordNet knowledge base. The construction procedure is both syntax- and semantics-aware. The samples enforce the model to ground learned embeddings to concrete concepts within the image. This simple but powerful technique brings a noticeable improvement over the baselines on a diverse set of downstream tasks, in addition to defending known-type adversarial attacks. We release the codes at https://github.com/ExplorerFreda/VSE-C.
PDF Abstract COLING 2018 PDF COLING 2018 Abstract


 MS COCO
MS COCO
