Less Is Better: Unweighted Data Subsampling via Influence Function
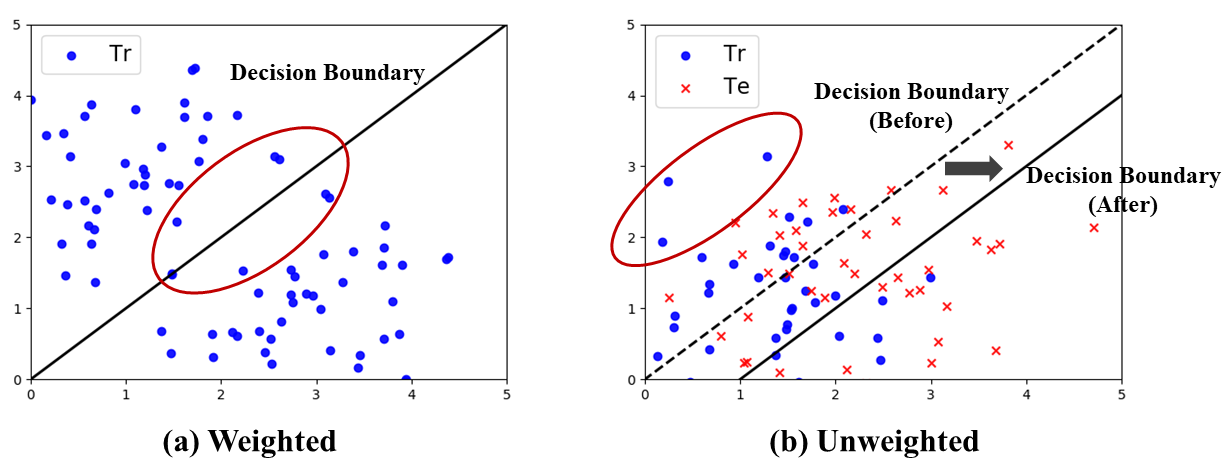
In the time of Big Data, training complex models on large-scale data sets is challenging, making it appealing to reduce data volume for saving computation resources by subsampling. Most previous works in subsampling are weighted methods designed to help the performance of subset-model approach the full-set-model, hence the weighted methods have no chance to acquire a subset-model that is better than the full-set-model. However, we question that how can we achieve better model with less data? In this work, we propose a novel Unweighted Influence Data Subsampling (UIDS) method, and prove that the subset-model acquired through our method can outperform the full-set-model. Besides, we show that overly confident on a given test set for sampling is common in Influence-based subsampling methods, which can eventually cause our subset-model's failure in out-of-sample test. To mitigate it, we develop a probabilistic sampling scheme to control the worst-case risk over all distributions close to the empirical distribution. The experiment results demonstrate our methods superiority over existed subsampling methods in diverse tasks, such as text classification, image classification, click-through prediction, etc.
PDF Abstract



