Leveraging Sparse Linear Layers for Debuggable Deep Networks
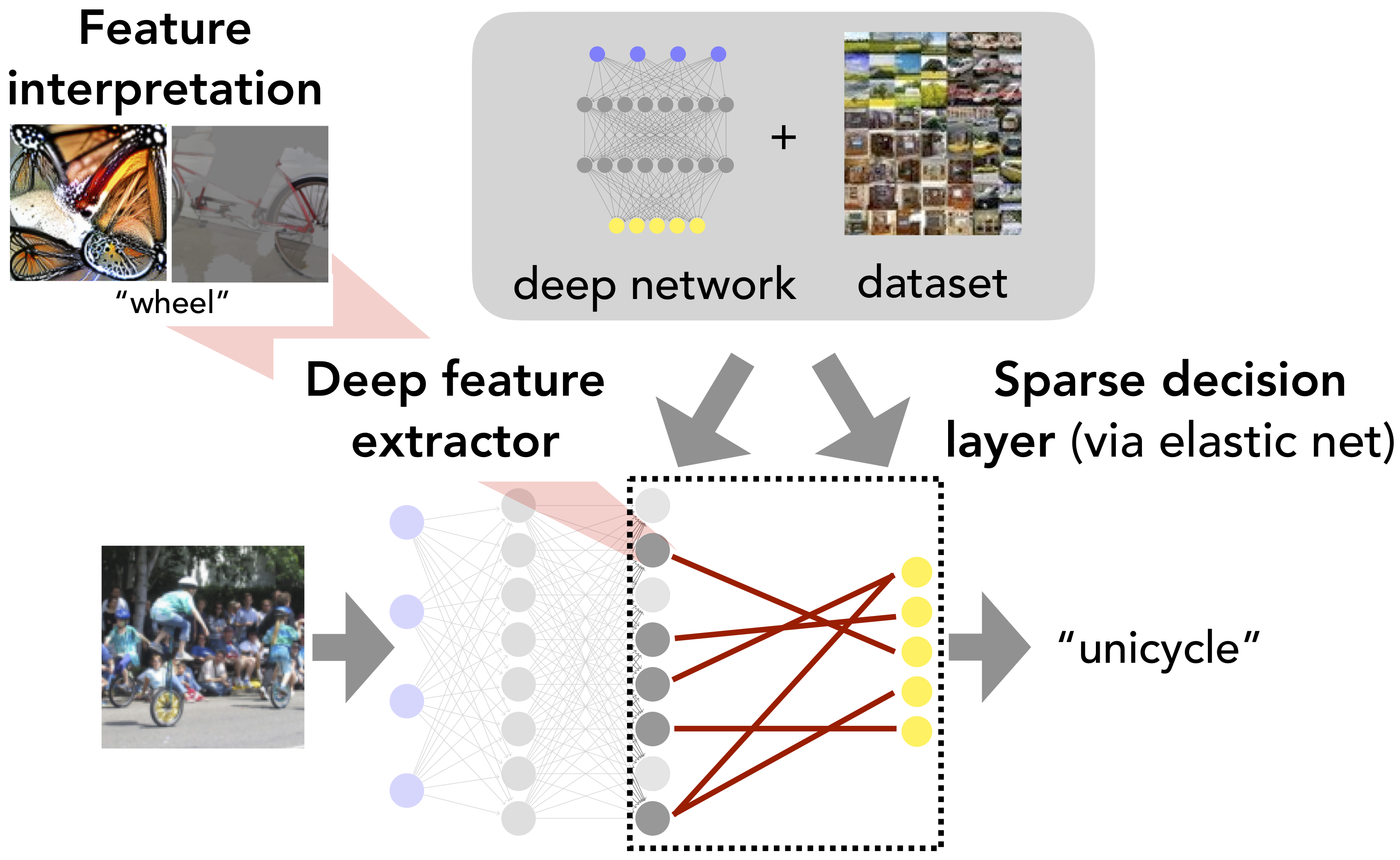
We show how fitting sparse linear models over learned deep feature representations can lead to more debuggable neural networks. These networks remain highly accurate while also being more amenable to human interpretation, as we demonstrate quantiatively via numerical and human experiments. We further illustrate how the resulting sparse explanations can help to identify spurious correlations, explain misclassifications, and diagnose model biases in vision and language tasks. The code for our toolkit can be found at https://github.com/madrylab/debuggabledeepnetworks.
PDF Abstract
Tasks
Datasets
 ImageNet
ImageNet
 SST
SST
 Places
Places
Results from the Paper
Submit
results from this paper
to get state-of-the-art GitHub badges and help the
community compare results to other papers.
Methods
No methods listed for this paper. Add
relevant methods here
