Lift, Splat, Shoot: Encoding Images From Arbitrary Camera Rigs by Implicitly Unprojecting to 3D
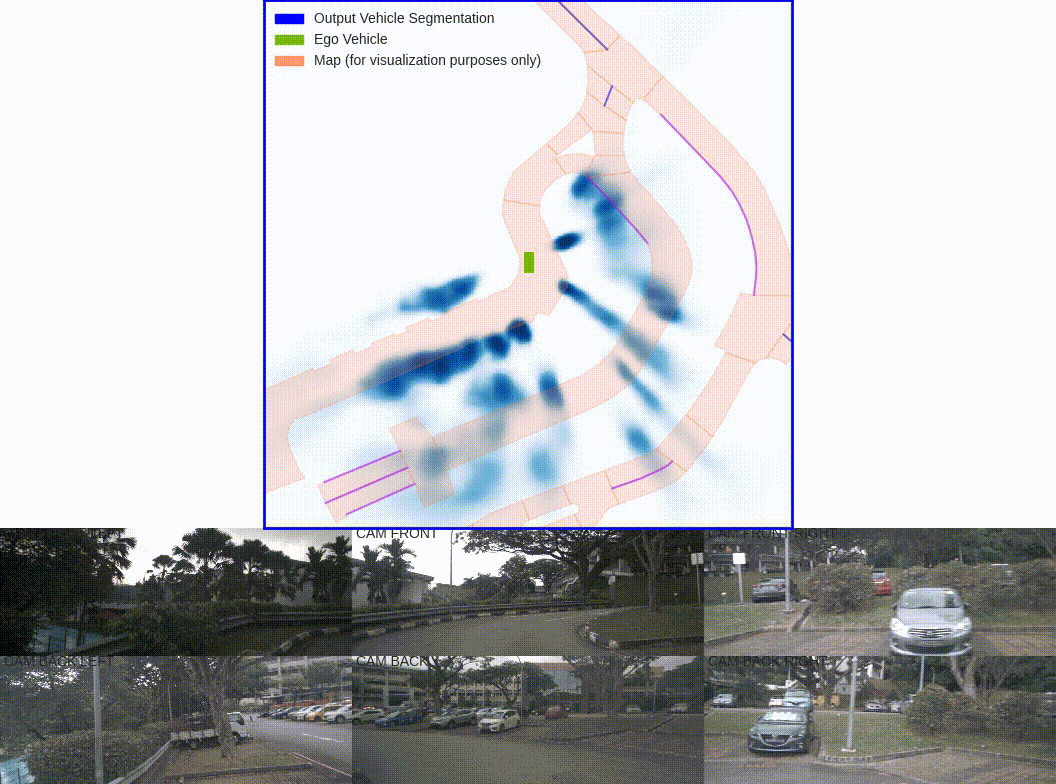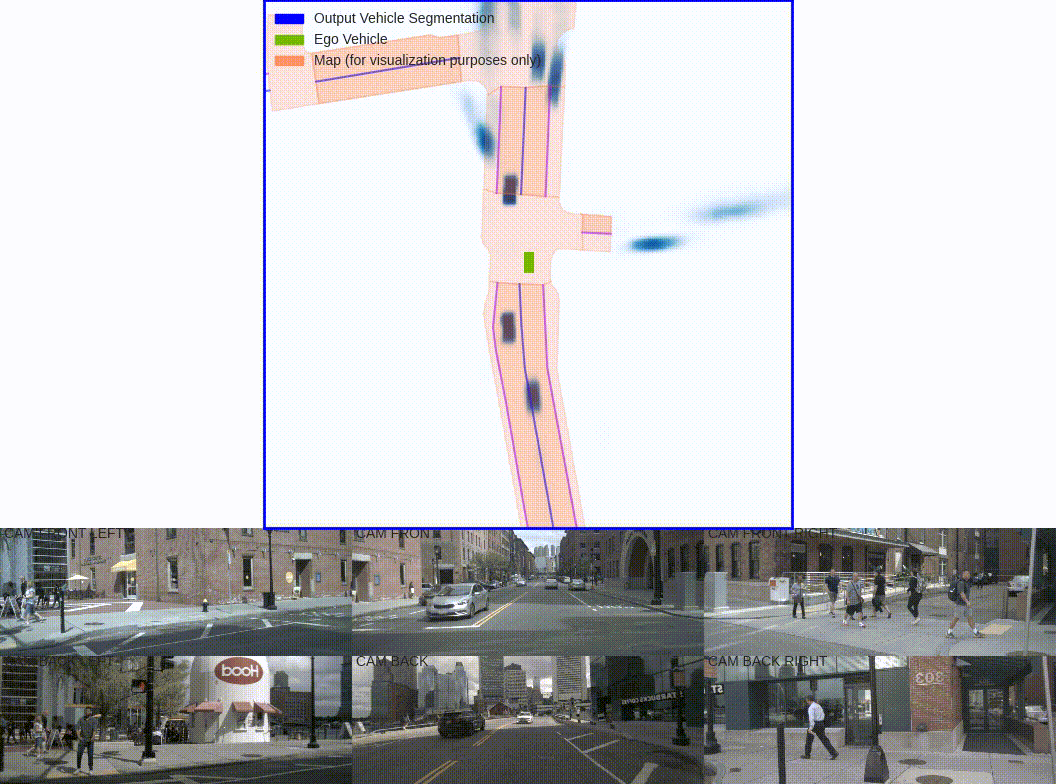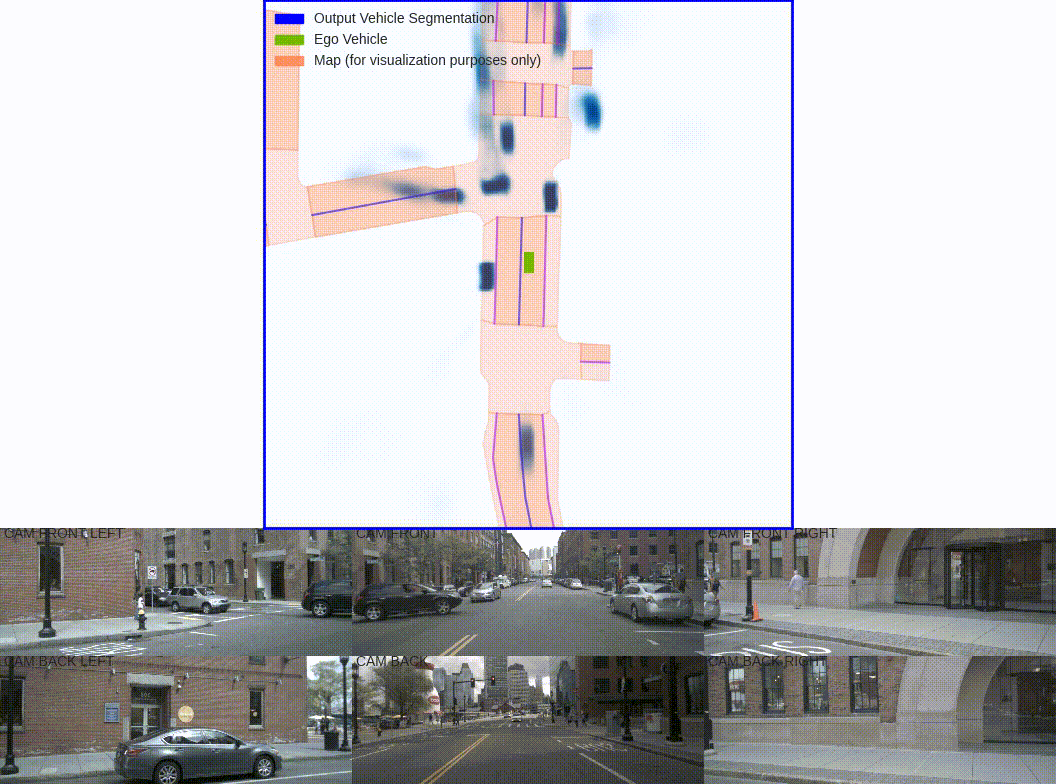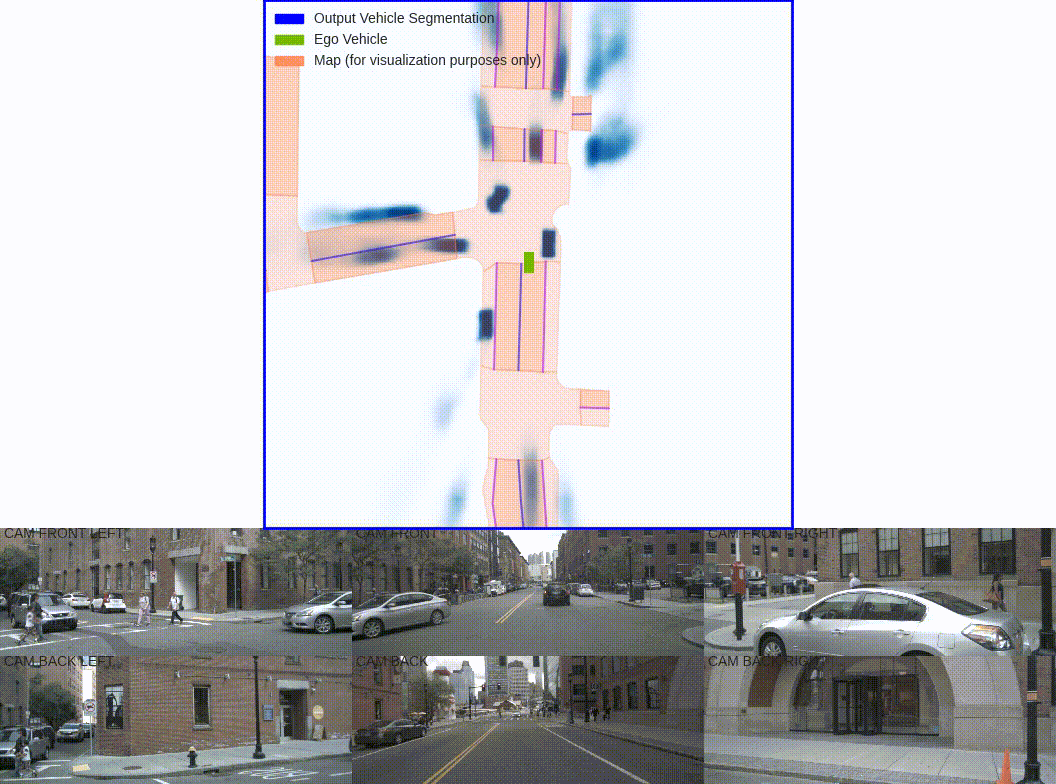
The goal of perception for autonomous vehicles is to extract semantic representations from multiple sensors and fuse these representations into a single "bird's-eye-view" coordinate frame for consumption by motion planning. We propose a new end-to-end architecture that directly extracts a bird's-eye-view representation of a scene given image data from an arbitrary number of cameras. The core idea behind our approach is to "lift" each image individually into a frustum of features for each camera, then "splat" all frustums into a rasterized bird's-eye-view grid. By training on the entire camera rig, we provide evidence that our model is able to learn not only how to represent images but how to fuse predictions from all cameras into a single cohesive representation of the scene while being robust to calibration error. On standard bird's-eye-view tasks such as object segmentation and map segmentation, our model outperforms all baselines and prior work. In pursuit of the goal of learning dense representations for motion planning, we show that the representations inferred by our model enable interpretable end-to-end motion planning by "shooting" template trajectories into a bird's-eye-view cost map output by our network. We benchmark our approach against models that use oracle depth from lidar. Project page with code: https://nv-tlabs.github.io/lift-splat-shoot .
PDF Abstract ECCV 2020 PDF ECCV 2020 AbstractCode





Datasets
 nuScenes
nuScenes
Results from the Paper
 Ranked #6 on
Bird's-Eye View Semantic Segmentation
on nuScenes
(IoU ped - 224x480 - Vis filter. - 100x100 at 0.5 metric)
Ranked #6 on
Bird's-Eye View Semantic Segmentation
on nuScenes
(IoU ped - 224x480 - Vis filter. - 100x100 at 0.5 metric)
