Lifting the Curse of Capacity Gap in Distilling Language Models
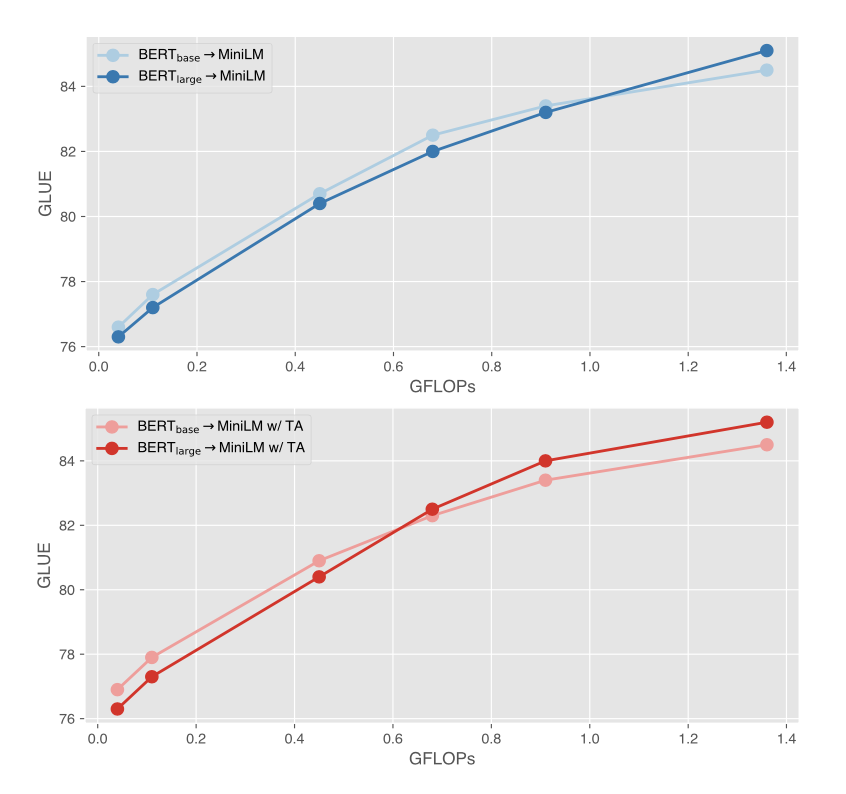
Pretrained language models (LMs) have shown compelling performance on various downstream tasks, but unfortunately they require a tremendous amount of inference compute. Knowledge distillation finds a path to compress LMs to small ones with a teacher-student paradigm. However, when the capacity gap between the teacher and the student is large, a curse of capacity gap appears, invoking a deficiency in distilling LMs. While a few studies have been carried out to fill the gap, the curse is not yet well tackled. In this paper, we aim at lifting the curse of capacity gap via enlarging the capacity of the student without notably increasing the inference compute. Largely motivated by sparse activation regime of mixture of experts (MoE), we propose a mixture of minimal experts (MiniMoE), which imposes extra parameters to the student but introduces almost no additional inference compute. Experimental results on GLUE and CoNLL demonstrate the curse of capacity gap is lifted by the magic of MiniMoE to a large extent. MiniMoE also achieves the state-of-the-art performance at small FLOPs compared with a range of competitive baselines. With a compression rate as much as $\sim$50$\times$, MiniMoE preserves $\sim$95\% GLUE score of the teacher.
PDF Abstract

 GLUE
GLUE
 SST
SST
 MultiNLI
MultiNLI
 QNLI
QNLI
 MRPC
MRPC
 CoLA
CoLA
