Location-aware Graph Convolutional Networks for Video Question Answering
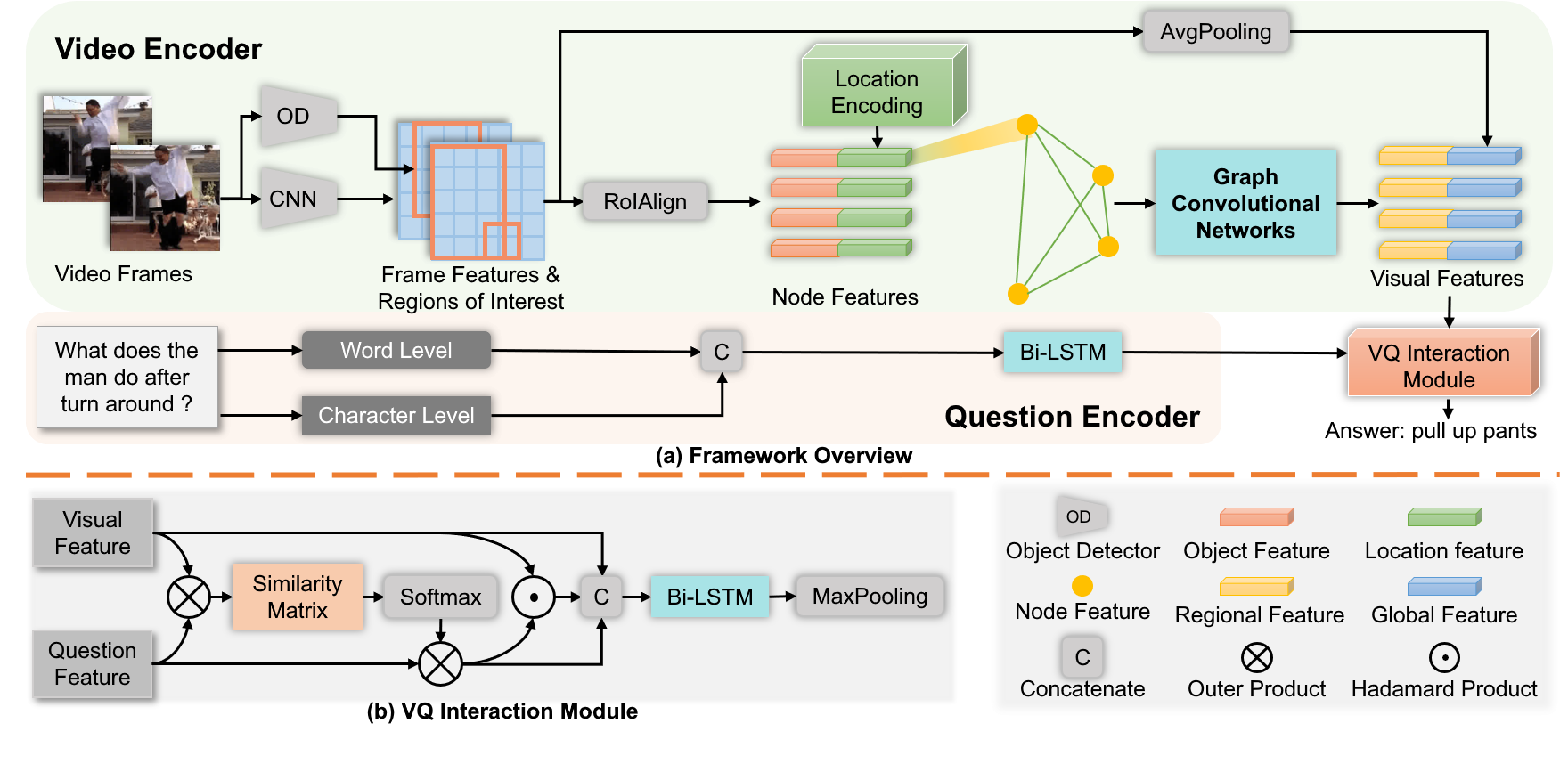
We addressed the challenging task of video question answering, which requires machines to answer questions about videos in a natural language form. Previous state-of-the-art methods attempt to apply spatio-temporal attention mechanism on video frame features without explicitly modeling the location and relations among object interaction occurred in videos. However, the relations between object interaction and their location information are very critical for both action recognition and question reasoning. In this work, we propose to represent the contents in the video as a location-aware graph by incorporating the location information of an object into the graph construction. Here, each node is associated with an object represented by its appearance and location features. Based on the constructed graph, we propose to use graph convolution to infer both the category and temporal locations of an action. As the graph is built on objects, our method is able to focus on the foreground action contents for better video question answering. Lastly, we leverage an attention mechanism to combine the output of graph convolution and encoded question features for final answer reasoning. Extensive experiments demonstrate the effectiveness of the proposed methods. Specifically, our method significantly outperforms state-of-the-art methods on TGIF-QA, Youtube2Text-QA, and MSVD-QA datasets. Code and pre-trained models are publicly available at: https://github.com/SunDoge/L-GCN
PDF Abstract



 MSVD
MSVD
 TGIF-QA
TGIF-QA
