Exploring Long Tail Visual Relationship Recognition with Large Vocabulary
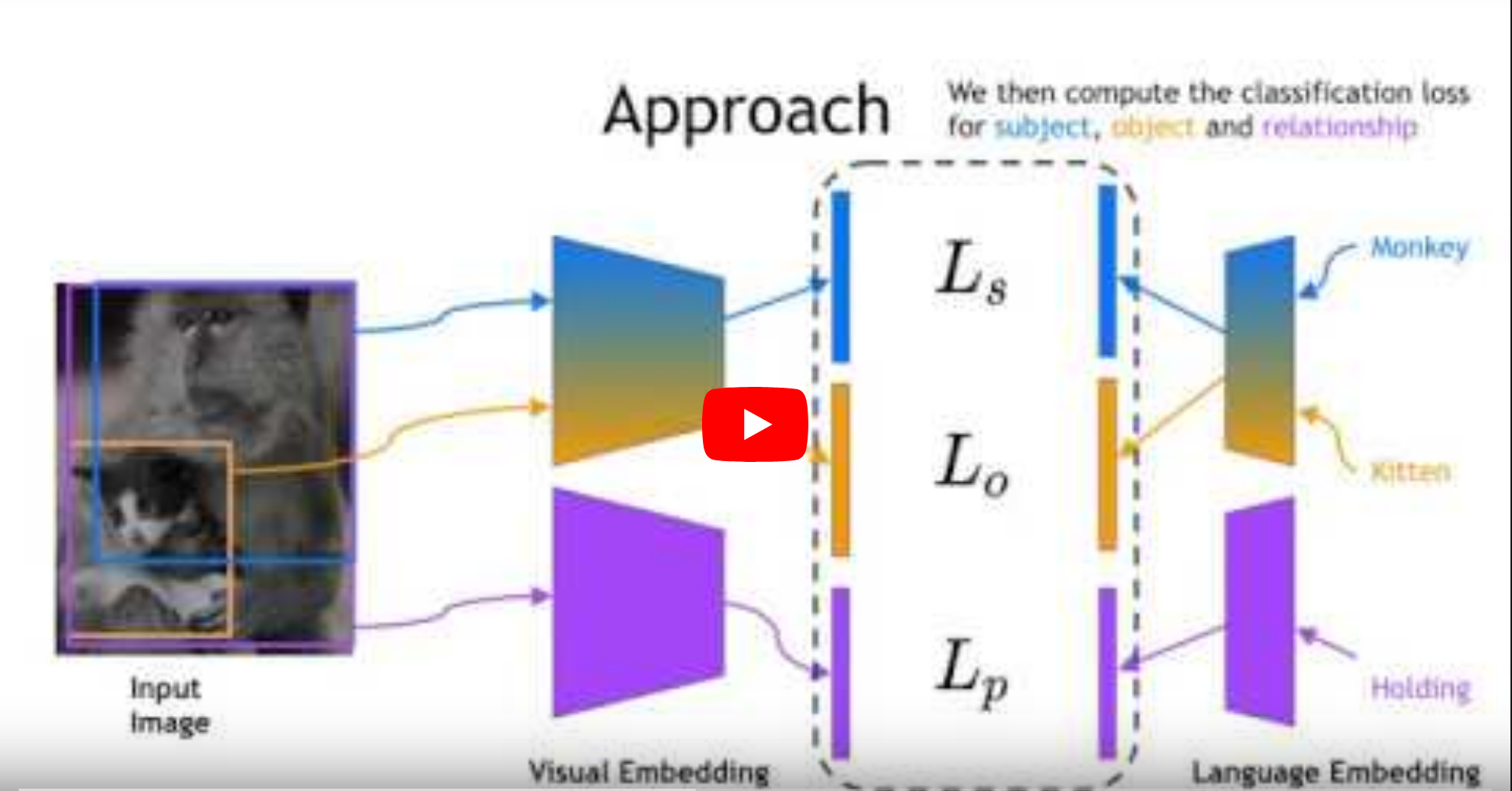
Several approaches have been proposed in recent literature to alleviate the long-tail problem, mainly in object classification tasks. In this paper, we make the first large-scale study concerning the task of Long-Tail Visual Relationship Recognition (LTVRR). LTVRR aims at improving the learning of structured visual relationships that come from the long-tail (e.g., "rabbit grazing on grass"). In this setup, the subject, relation, and object classes each follow a long-tail distribution. To begin our study and make a future benchmark for the community, we introduce two LTVRR-related benchmarks, dubbed VG8K-LT and GQA-LT, built upon the widely used Visual Genome and GQA datasets. We use these benchmarks to study the performance of several state-of-the-art long-tail models on the LTVRR setup. Lastly, we propose a visiolinguistic hubless (VilHub) loss and a Mixup augmentation technique adapted to LTVRR setup, dubbed as RelMix. Both VilHub and RelMix can be easily integrated on top of existing models and despite being simple, our results show that they can remarkably improve the performance, especially on tail classes. Benchmarks, code, and models have been made available at: https://github.com/Vision-CAIR/LTVRR.
PDF Abstract ICCV 2021 PDF ICCV 2021 Abstract

 Visual Genome
Visual Genome
 VRD
VRD
