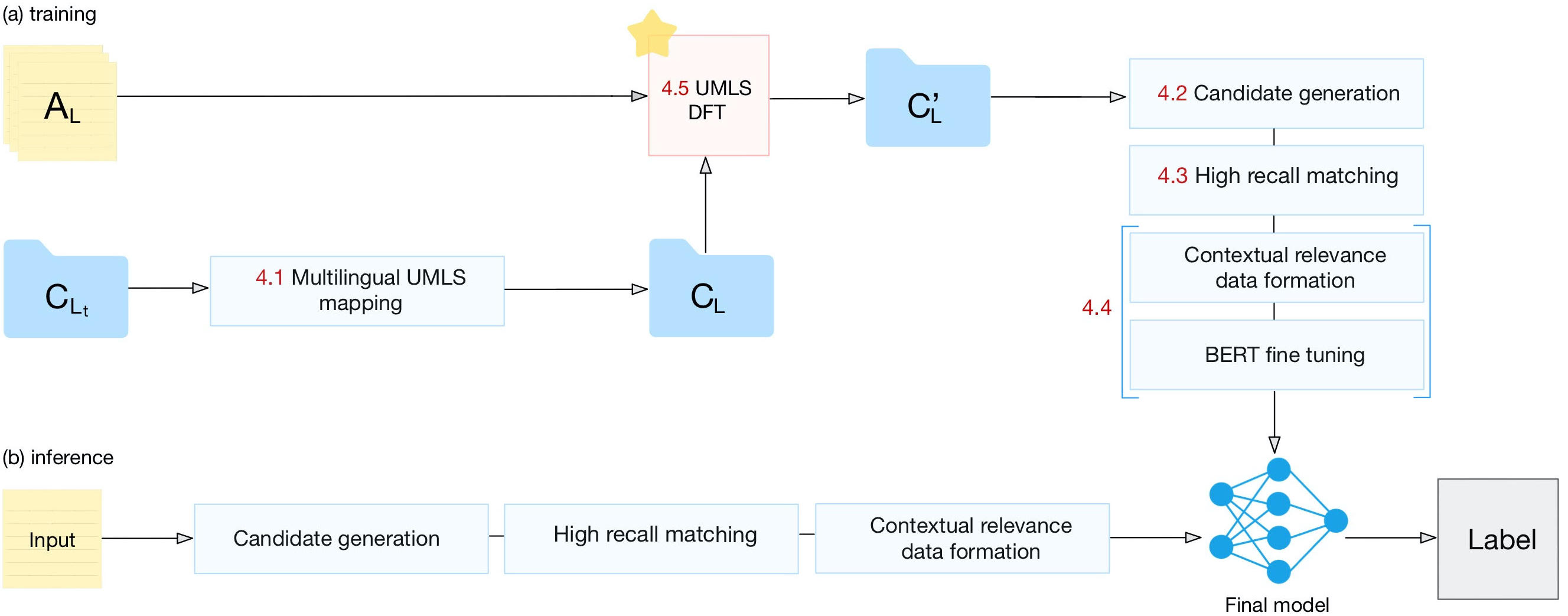
Low Resource Recognition and Linking of Biomedical Concepts from a Large Ontology
Tools to explore scientific literature are essential for scientists, especially in biomedicine, where about a million new papers are published every year. Many such tools provide users the ability to search for specific entities (e.g. proteins, diseases) by tracking their mentions in papers. PubMed, the most well known database of biomedical papers, relies on human curators to add these annotations. This can take several weeks for new papers, and not all papers get tagged. Machine learning models have been developed to facilitate the semantic indexing of scientific papers. However their performance on the more comprehensive ontologies of biomedical concepts does not reach the levels of typical entity recognition problems studied in NLP. In large part this is due to their low resources, where the ontologies are large, there is a lack of descriptive text defining most entities, and labeled data can only cover a small portion of the ontology. In this paper, we develop a new model that overcomes these challenges by (1) generalizing to entities unseen at training time, and (2) incorporating linking predictions into the mention segmentation decisions. Our approach achieves new state-of-the-art results for the UMLS ontology in both traditional recognition/linking (+8 F1 pts) as well as semantic indexing-based evaluation (+10 F1 pts).
PDF Abstract

 MedMentions
MedMentions
