Masked Motion Encoding for Self-Supervised Video Representation Learning
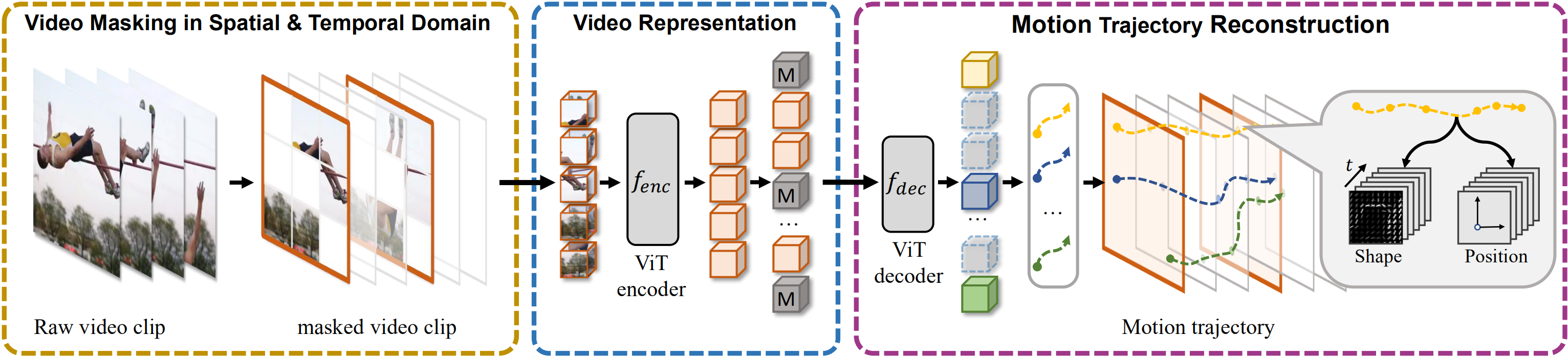
How to learn discriminative video representation from unlabeled videos is challenging but crucial for video analysis. The latest attempts seek to learn a representation model by predicting the appearance contents in the masked regions. However, simply masking and recovering appearance contents may not be sufficient to model temporal clues as the appearance contents can be easily reconstructed from a single frame. To overcome this limitation, we present Masked Motion Encoding (MME), a new pre-training paradigm that reconstructs both appearance and motion information to explore temporal clues. In MME, we focus on addressing two critical challenges to improve the representation performance: 1) how to well represent the possible long-term motion across multiple frames; and 2) how to obtain fine-grained temporal clues from sparsely sampled videos. Motivated by the fact that human is able to recognize an action by tracking objects' position changes and shape changes, we propose to reconstruct a motion trajectory that represents these two kinds of change in the masked regions. Besides, given the sparse video input, we enforce the model to reconstruct dense motion trajectories in both spatial and temporal dimensions. Pre-trained with our MME paradigm, the model is able to anticipate long-term and fine-grained motion details. Code is available at https://github.com/XinyuSun/MME.
PDF Abstract CVPR 2023 PDF CVPR 2023 Abstract




 UCF101
UCF101
 HMDB51
HMDB51
 Something-Something V2
Something-Something V2

