Making Pre-trained Language Models Better Few-shot Learners
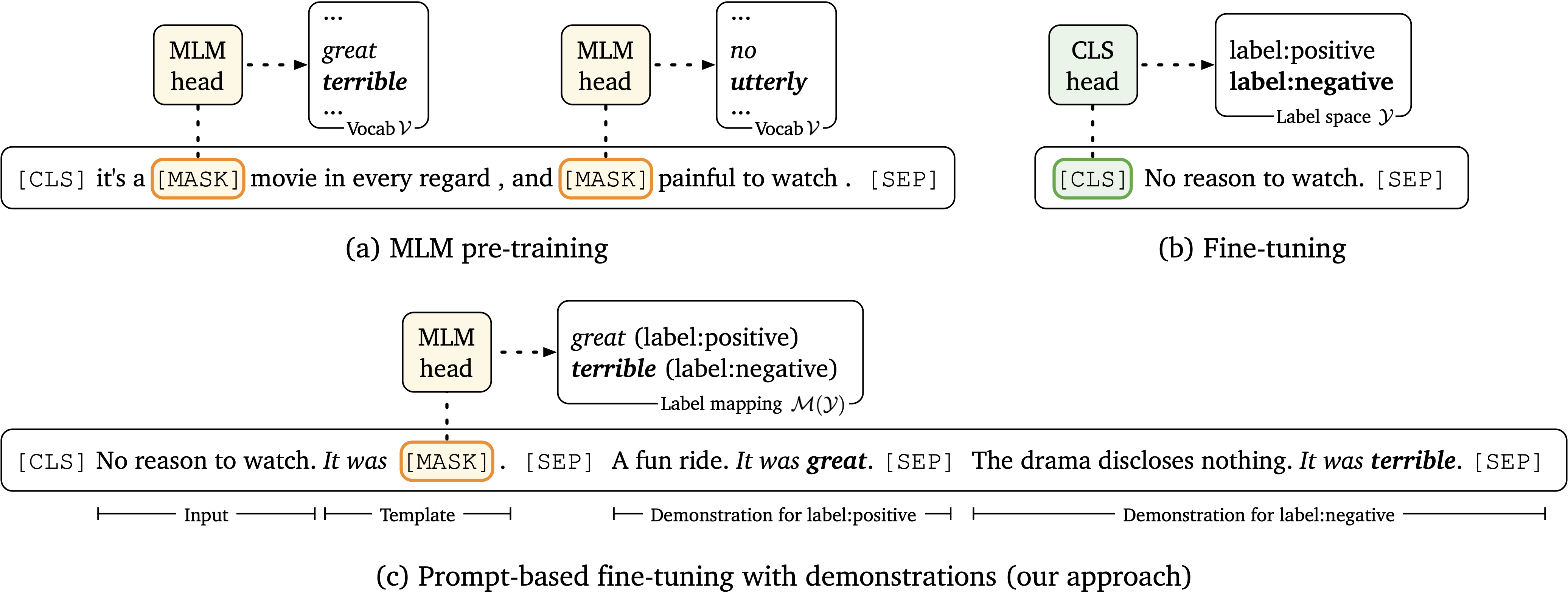
The recent GPT-3 model (Brown et al., 2020) achieves remarkable few-shot performance solely by leveraging a natural-language prompt and a few task demonstrations as input context. Inspired by their findings, we study few-shot learning in a more practical scenario, where we use smaller language models for which fine-tuning is computationally efficient. We present LM-BFF--better few-shot fine-tuning of language models--a suite of simple and complementary techniques for fine-tuning language models on a small number of annotated examples. Our approach includes (1) prompt-based fine-tuning together with a novel pipeline for automating prompt generation; and (2) a refined strategy for dynamically and selectively incorporating demonstrations into each context. Finally, we present a systematic evaluation for analyzing few-shot performance on a range of NLP tasks, including classification and regression. Our experiments demonstrate that our methods combine to dramatically outperform standard fine-tuning procedures in this low resource setting, achieving up to 30% absolute improvement, and 11% on average across all tasks. Our approach makes minimal assumptions on task resources and domain expertise, and hence constitutes a strong task-agnostic method for few-shot learning.
PDF Abstract ACL 2021 PDF ACL 2021 Abstract

 GLUE
GLUE
 SST
SST
 MultiNLI
MultiNLI
 SNLI
SNLI
 QNLI
QNLI
 AG News
AG News
 MRPC
MRPC
 CoLA
CoLA
 MPQA Opinion Corpus
MPQA Opinion Corpus

