ManiFest: Manifold Deformation for Few-shot Image Translation
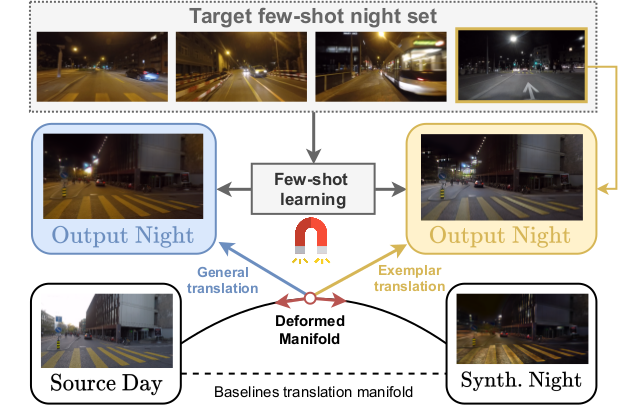
Most image-to-image translation methods require a large number of training images, which restricts their applicability. We instead propose ManiFest: a framework for few-shot image translation that learns a context-aware representation of a target domain from a few images only. To enforce feature consistency, our framework learns a style manifold between source and proxy anchor domains (assumed to be composed of large numbers of images). The learned manifold is interpolated and deformed towards the few-shot target domain via patch-based adversarial and feature statistics alignment losses. All of these components are trained simultaneously during a single end-to-end loop. In addition to the general few-shot translation task, our approach can alternatively be conditioned on a single exemplar image to reproduce its specific style. Extensive experiments demonstrate the efficacy of ManiFest on multiple tasks, outperforming the state-of-the-art on all metrics and in both the general- and exemplar-based scenarios. Our code is available at https://github.com/cv-rits/Manifest .
PDF Abstract


 Cityscapes
Cityscapes
